|
Today, we’re announcing the general availability of AWS Lambda SnapStart for Python and .NET functions that delivers faster function startup performance, from several seconds to as low as sub-second, typically with minimal or no code changes in Python, C#, F#, and Powershell.
In November 28, 2022, we introduced Lambda SnapStart for Java functions to improve startup performance by up to 10 times. With Lambda SnapStart, you can reduce outlier latencies that come from initializing functions, without having to provision resources or spend time implementing complex performance optimizations.
Lambda SnapStart works by caching and reusing the snapshotted memory and disk state of any one-time initialization code, or code that runs only the first time a Lambda function is invoked. Lambda takes a Firecracker microVM snapshot of the memory and disk state of the initialized execution environment, encrypts the snapshot, and caches it for low-latency access.

When you invoke the function version for the first time, and as the invocations scale up, Lambda resumes new execution environments from the cached snapshot instead of initializing them from scratch, improving startup latency. Lambda SnapStart makes it easy to build highly scalable and responsive applications in Python and .NET using AWS Lambda.
For Python functions, startup latency from initialization code can be several seconds long. Some scenarios where this can occur are – loading dependencies (such as LangChain, Numpy, Pandas, and DuckDB) or using frameworks (such as Flask or Django). Many functions also perform machine learning (ML) inference using Lambda, and need to load ML models during initialization – a process that can take tens of seconds depending on the size of the model used. Using Lambda SnapStart can reduce startup latency from several seconds to as low as sub-second for these scenarios.
For .NET functions, we expect most use cases to benefit because .NET just-in-time (JIT) compilation takes up to several seconds. Latency variability associated with initialization of Lambda functions has been a long-standing barrier for customers to use .NET for AWS Lambda. SnapStart enables functions to resume quickly by caching a snapshot of their memory and disk state. Therefore, most .NET functions will experience significant improvement in latency variability with Lambda SnapStart.
Getting started with Lambda SnapStart for Python and .NET
To get started, you can use the AWS Management Console, AWS Command Line Interface (AWS CLI) or AWS SDKs to activate, update, and delete SnapStart for Python and .NET functions.
On the AWS Lambda console, go to the Functions page and choose your function to use Lambda SnapStart. Select Configuration, choose General configuration, and then choose Edit. You can see SnapStart settings on the Edit basic settings page.
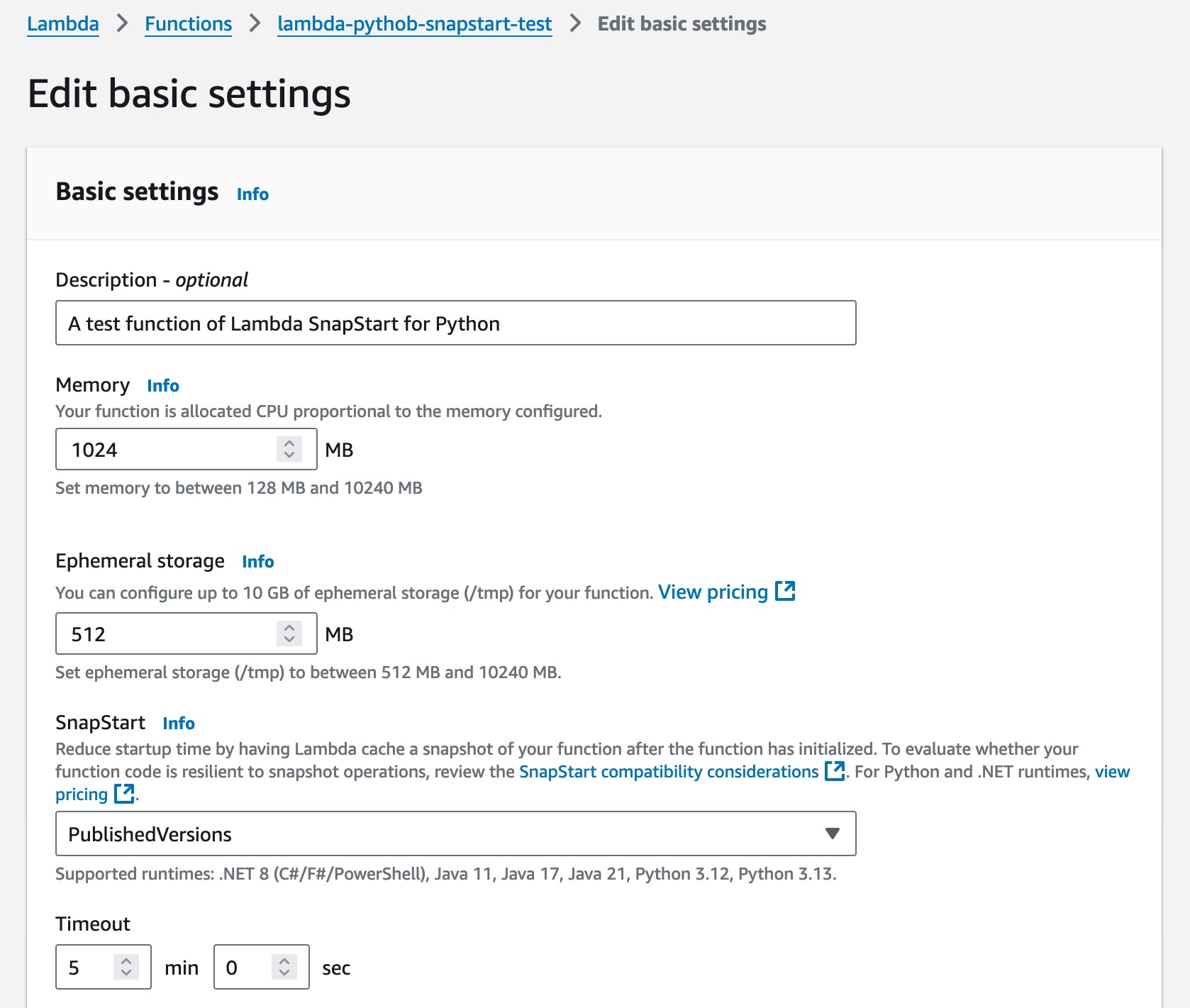
You can activate Lambda functions using Python 3.12 and higher, and .NET 8 and higher managed runtimes. Choose Published versions and then choose Save.
When you publish a new version of your function, Lambda initializes your code, creates a snapshot of the initialized execution environment, and then caches the snapshot for low-latency access. You can invoke the function to confirm activation of SnapStart.
Here is an AWS CLI command to update the function configuration by running the update-function-configuration command with the --snap-start option.
aws lambda update-function-configuration
--function-name lambda-python-snapstart-test
--snap-start ApplyOn=PublishedVersionsPublish a function version with the publish-version command.
aws lambda publish-version
--function-name lambda-python-snapstart-testConfirm that SnapStart is activated for the function version by running the get-function-configuration command and specifying the version number.
aws lambda get-function-configuration
--function-name lambda-python-snapstart-test:1If the response shows that OptimizationStatus is On and State is Active, then SnapStart is activated, and a snapshot is available for the specified function version.
"SnapStart": {
"ApplyOn": "PublishedVersions",
"OptimizationStatus": "On"
},
"State": "Active",To learn more about activating, updating, and deleting a snapshot with AWS SDKs, AWS CloudFormation, AWS Serverless Application Model (AWS SAM), and AWS Cloud Development Kit (AWS CDK), visit Activating and managing Lambda SnapStart in the AWS Lambda Developer Guide.
Runtime hooks
You can use runtime hooks to run code executed before Lambda creates a snapshot or after Lambda resumes a function from a snapshot. Runtime hooks are useful to perform cleanup or resource release operations, dynamically update configuration or other metadata, integrate with external services or systems, such as sending notifications or updating external state or to fine-tune your function’s startup sequence, such as by preloading dependencies.
Python runtime hooks are available as part of the open source Snapshot Restore for Python library, which is included in Python managed runtime. This library provides two decorators @register_before_snapshot to run before Lambda creates a snapshot and @register_after_restore to run when Lambda resumes a function from a snapshot. To learn more, visit Lambda SnapStart runtime hooks for Python in the AWS Lambda Developer Guide.
Here is an example Python handler to show how to run code before checkpointing and after restoring:
from snapshot_restore_py import register_before_snapshot, register_after_restore
def lambda_handler(event, context):
# handler code
@register_before_snapshot
def before_checkpoint():
# Logic to be executed before taking snapshots
@register_after_restore
def after_restore():
# Logic to be executed after restoreYou can also use .NET runtime hooks available as part of the Amazon.Lambda.Core package (version 2.5 or later) from NuGet. This library provides two methods RegisterBeforeSnapshot() to run before snapshot creation and RegisterAfterRestore() to run after resuming a function from a snapshot. To learn more, visit Lambda SnapStart runtime hooks for .NET in the AWS Lambda Developer Guide.
Here is an example C# handler to show how to run code before checkpointing and after restoring:
public class SampleClass
{
public SampleClass()
{
Amazon.Lambda.Core.SnapshotRestore.RegisterBeforeSnapshot(BeforeCheckpoint);
Amazon.Lambda.Core.SnapshotRestore.RegisterAfterRestore(AfterRestore);
}
private ValueTask BeforeCheckpoint()
{
// Add logic to be executed before taking the snapshot
return ValueTask.CompletedTask;
}
private ValueTask AfterRestore()
{
// Add logic to be executed after restoring the snapshot
return ValueTask.CompletedTask;
}
public APIGatewayProxyResponse FunctionHandler(APIGatewayProxyRequest request, ILambdaContext context)
{
// INSERT business logic
return new APIGatewayProxyResponse
{
StatusCode = 200
};
}
}To learn how to implement runtime hooks for your preferred runtime, visit Implement code before or after Lambda function snapshots in the AWS Lambda Developer Guide.
Things to know
Here are some things that you should know about Lambda SnapStart:
- Handling uniqueness – If your initialization code generates unique content that is included in the snapshot, then the content will not be unique when it’s reused across execution environments. To maintain uniqueness when using SnapStart, you must generate unique content after initialization, such as if your code uses custom random number generation that doesn’t rely on built-in-libraries or caches any information such as DNS entries that might expire during initialization. To learn how to restore uniqueness, visit Handling uniqueness with Lambda SnapStart in the AWS Lambda Developer Guide.
- Performance tuning – To maximize the performance, we recommend that you preload dependencies and initialize resources that contribute to startup latency in your initialization code instead of in the function handler. This moves the latency associated with heavy class loading out of the invocation path, optimizing startup performance with SnapStart.
- Networking best practices –The state of connections that your function establishes during the initialization phase isn’t guaranteed when Lambda resumes your function from a snapshot. In most cases, network connections that an AWS SDK establishes automatically resume. For other connections, review the Maximize Lambda SnapStart performance in the AWS Lambda Developer Guide.
- Monitoring functions – You can monitor your SnapStart functions using Amazon CloudWatch log stream, AWS X-Ray active tracing, and accessing real-time telemetry data for extensions using the Telemetry API, Amazon API Gateway and function URL metrics. To learn more about differences for SnapStart functions, visit Monitoring for Lambda SnapStart in the AWS Lambda Developer Guide.
Now available
AWS Lambda SnapStart for Python and .NET functions are available today in US East (N. Virginia), US East (Ohio), US West (Oregon), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Europe (Frankfurt), Europe (Ireland), and Europe (Stockholm) AWS Regions.
With the Python and .NET managed runtimes, there are two types of SnapStart charges: the cost of caching a snapshot per function version that you publish with SnapStart enabled, and the cost of restoration each time a function instance is restored from a snapshot. So, delete unused function versions to reduce your SnapStart cache costs. To learn more, visit the AWS Lambda pricing page.
Give Lambda SnapStart for Python and .NET a try in the AWS Lambda console. To learn more, visit Lambda SnapStart page and send feedback through AWS re:Post for AWS Lambda or your usual AWS Support contacts.
— Channy