|
As a data scientist, I’ve experienced firsthand the challenges of making machine learning (ML) accessible to business analysts, marketing analysts, data analysts, and data engineers who are experts in their domains without ML experience. That’s why I’m particularly excited about today’s Amazon Web Services (AWS) announcement that Amazon Q Developer is now available in Amazon SageMaker Canvas. What catches my attention is how Amazon Q Developer helps connect ML expertise with business needs, making ML more accessible across organizations.
Amazon Q Developer helps domain experts build accurate, production-quality ML models through natural language interactions, even if they don’t have ML expertise. Amazon Q Developer guides these users by breaking down their business problems and analyzing their data to recommend step-by-step guidance for building custom ML models. It transforms users’ data to remove anomalies, and builds and evaluates custom ML models to recommend the best one, while providing users control and visibility into every step of the guided ML workflow. This empowers organizations to innovate faster with reduced time to market. It also reduces their reliance on ML experts so their specialists can focus on more complex technical challenges.
For example, a marketing analyst can state, “I want to predict home sales prices using home characteristics and past sales data”, and Amazon Q Developer will translate this into a set of ML steps, analyzing relevant customer data, building multiple models, and recommending the best approach.
Let’s see it in action
To start using Amazon Q Developer, I follow the Getting started with using Amazon SageMaker Canvas guide to launch the Canvas application. In this demo, I use natural language instructions to create a model to predict house prices for marketing and finance teams. From the SageMaker Canvas page, I select Amazon Q and then choose Start a new conversation.

In the new conversation I write:
I am an analyst and need to predict house prices for my marketing and finance teams.

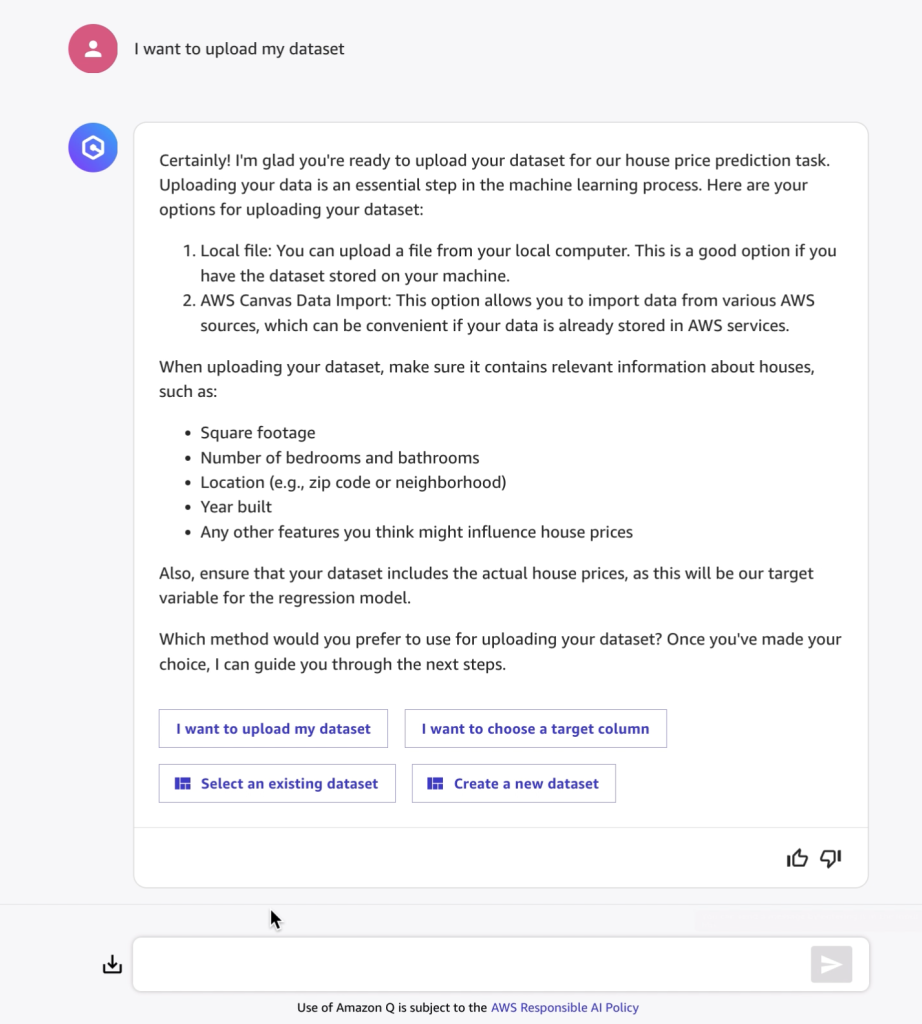
Next, Amazon Q Developer explains the problem and recommends the appropriate ML model type. It also outlines the solution requirements, including the necessary dataset characteristics. Amazon Q Developer then asks if I want to upload my dataset or I want to choose a target column. I select it to upload my dataset.
In the next step, Amazon Q Developer lists the dataset requirements, which include relevant information about houses, current house prices, and the target variable for the regression model. It then recommended next steps, including: I want to upload my dataset, Select an existing dataset, Create a new dataset or I want to choose a target column. For this demo, I’ll use the canvas-sample-housing.csv sample dataset as my existing dataset.
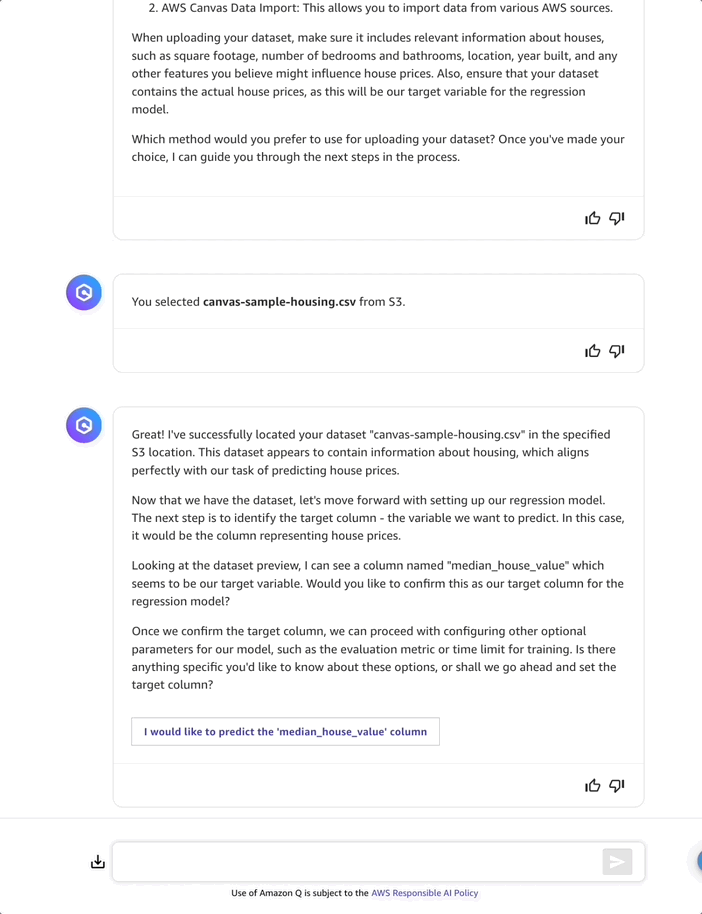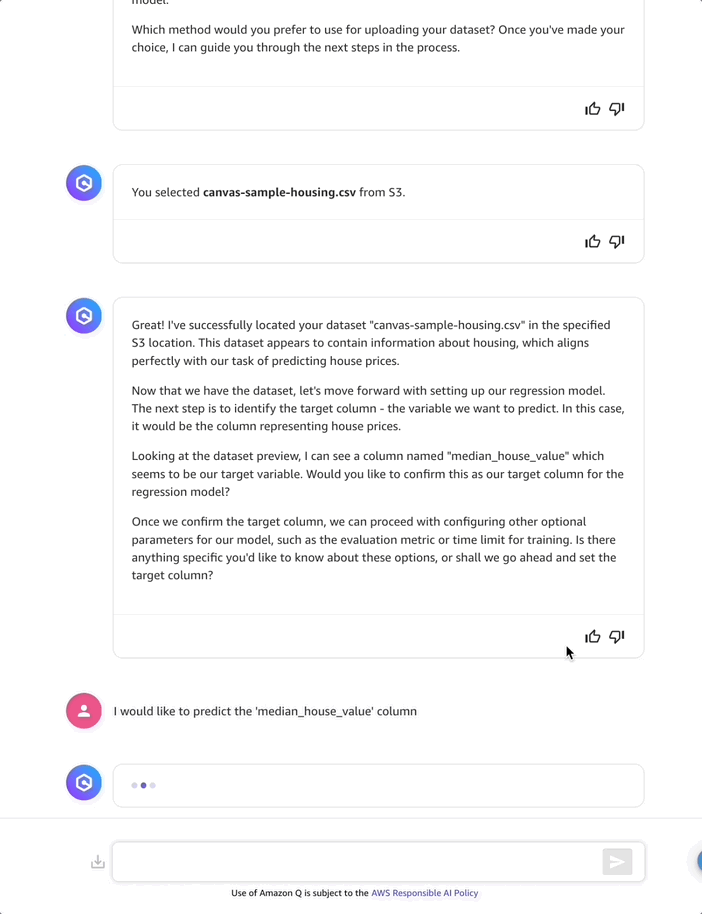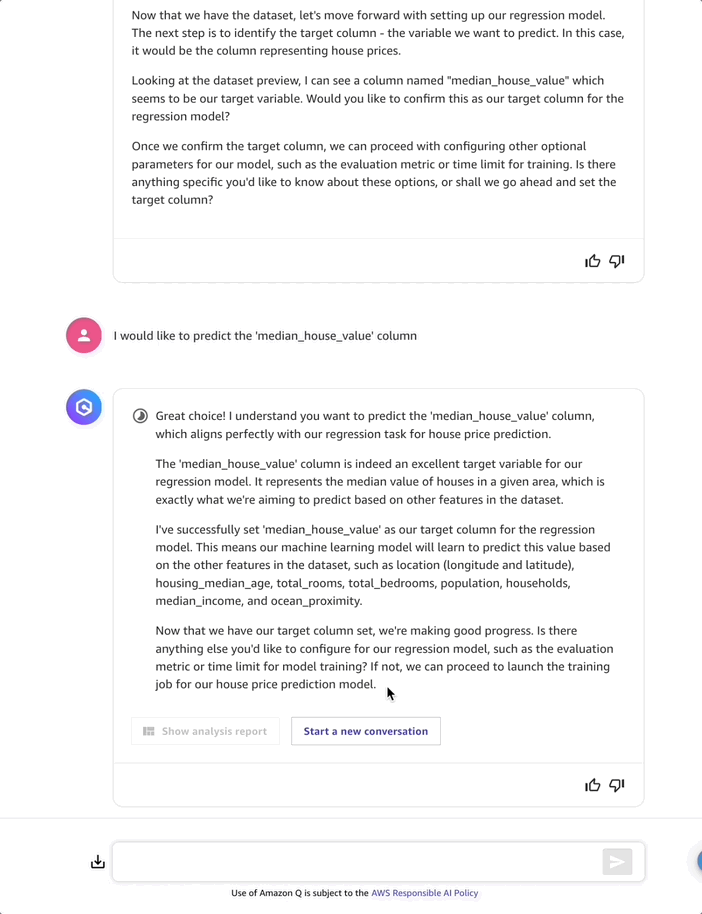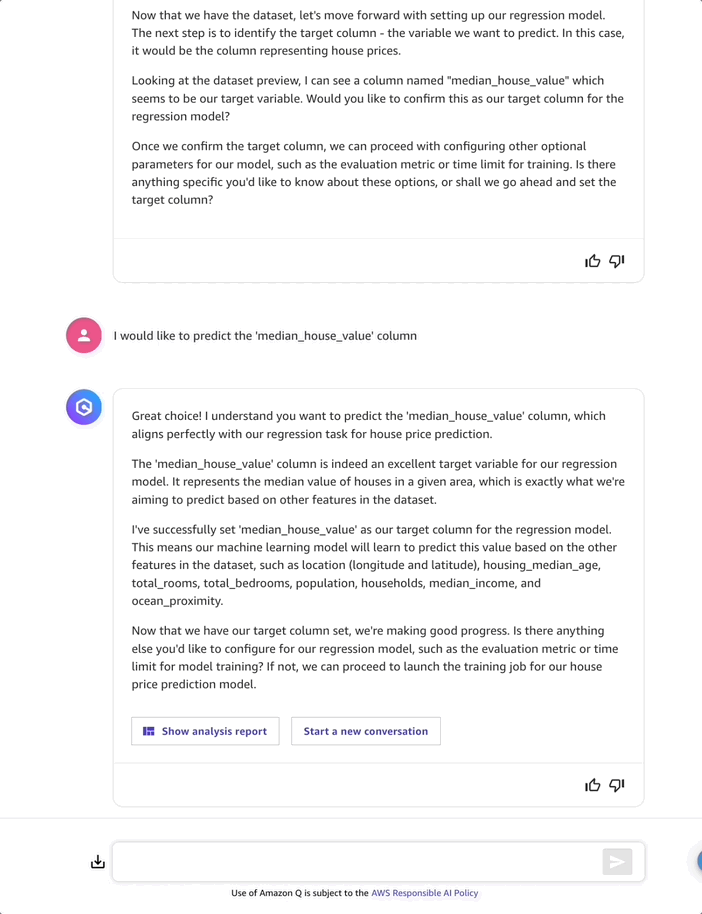
After selecting and loading the dataset, Amazon Q Developer analyzes it and suggests median_house_value as the target column for the regression model. I accept by selecting I would like to predict the “median_house_value” column. Moving on to the next step, Amazon Q Developer details which dataset features (such as “location”, “housing_median_age”, and “total_rooms”) it will use to predict the median_house_value.
Before moving forward with model training, I ask about the data quality, because without good data we can’t build a reliable model. Amazon Q Developer responds with quality insights for my entire dataset.
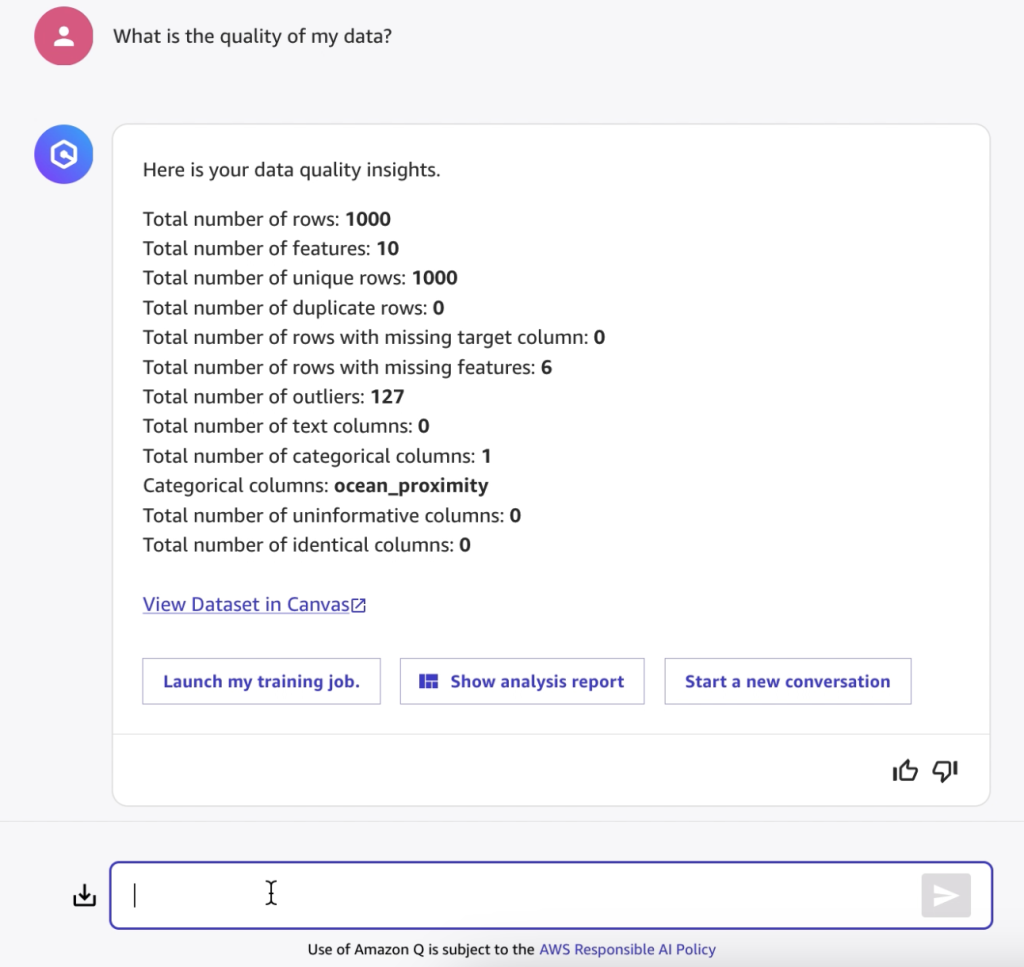
I can ask specific questions about individual features and their distributions to better understand the data quality.

To my surprise, through the previous question, I discovered that the “households” column has a wide variation between extreme values, which could affect the model’s prediction accuracy. Therefore, I ask Amazon Q Developer to fix this outlier problem.

After the transformation is done, I can ask what steps Amazon Q Developer followed to make this change. Behind the scenes, Amazon Q Developer applies advanced data preparation steps using SageMaker Canvas data preparation capabilities, which I can review and see the steps so that I can visualize and replicate the process to get the final, prepared dataset for training the model.
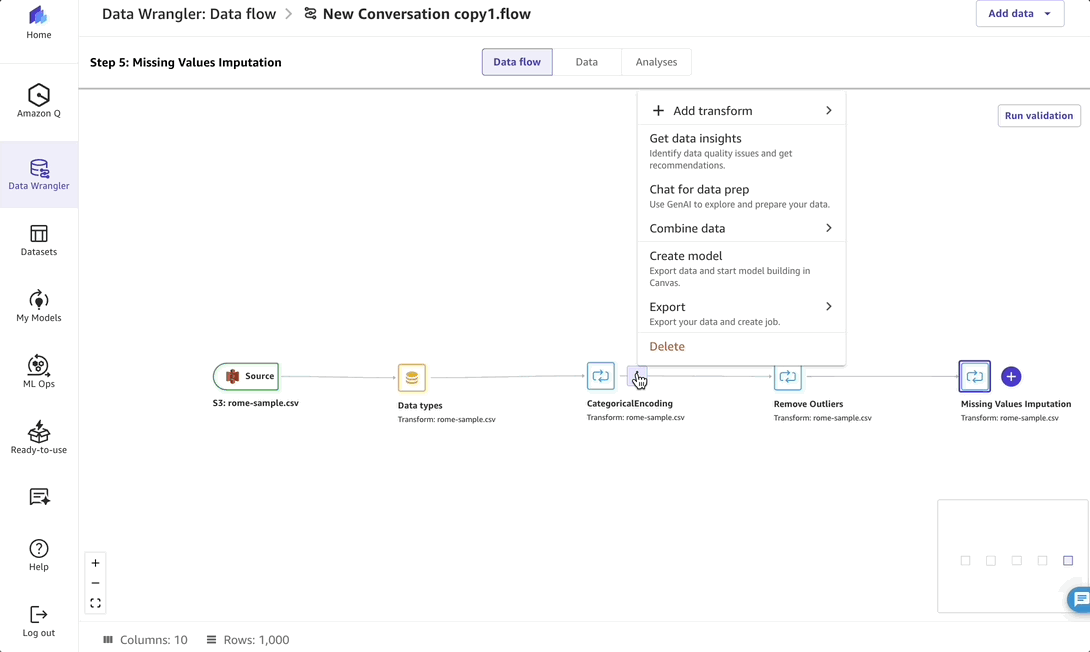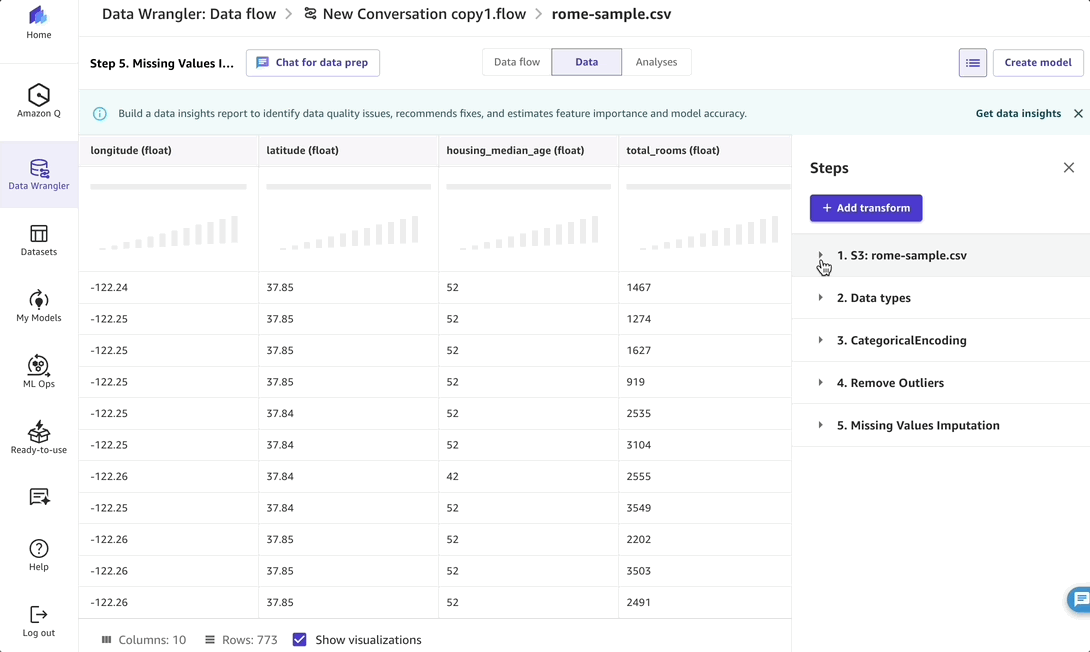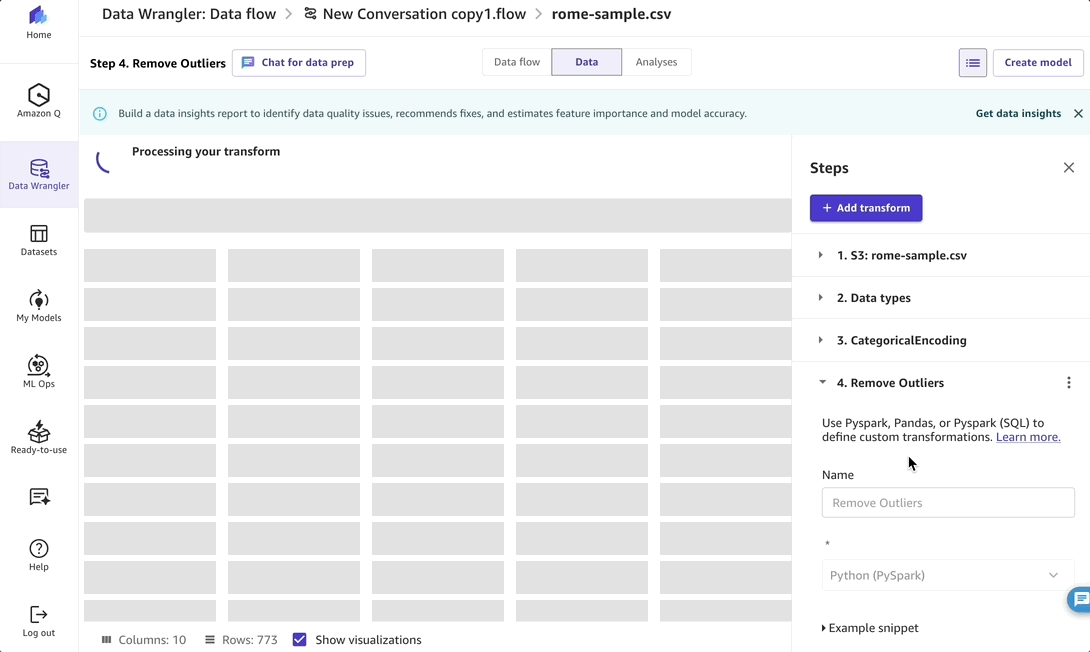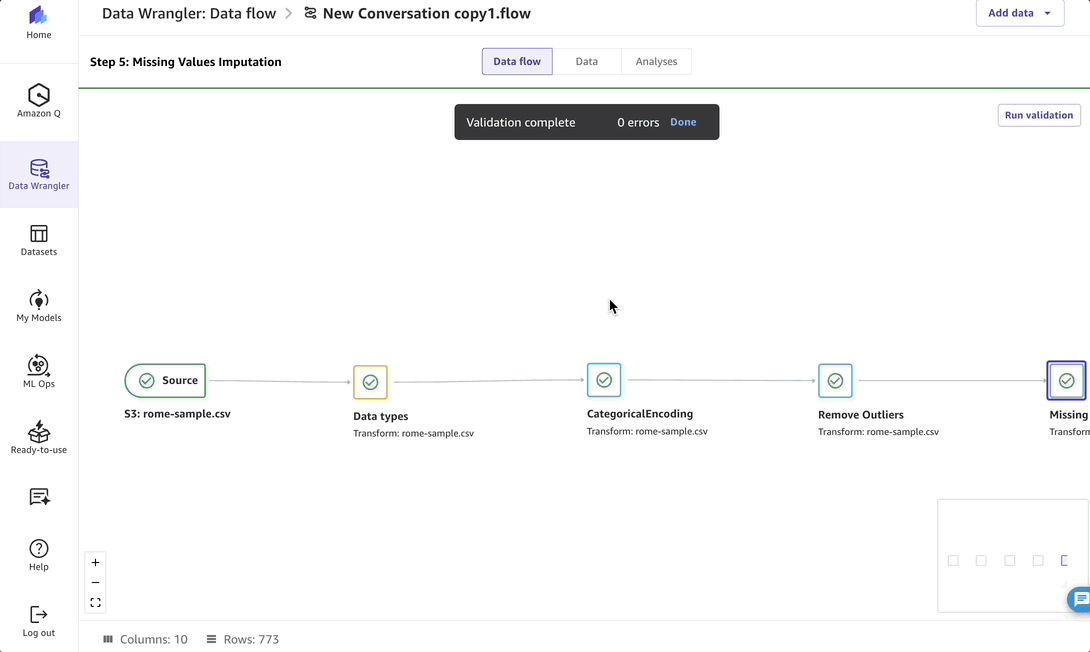
After reviewing the data preparation steps, I select Launch my training job.

After the training job is launched, I can see its progress in the conversation, and the datasets created.

As a data scientist, I particularly appreciate that, with Amazon Q Developer, Ican see detailed metrics such as the confusion matrix and precision-recall scores for classification models and root mean square error (RMSE) for regression models. These are crucial elements I always look for when evaluating model performance and making data-driven decisions, and it’s refreshing to see them presented in a way that’s accessible to nontechnical users to build trust and enable proper governance while maintaining the depth that technical teams need.
You can access these metrics by selecting the new model from My Models or from the Amazon Q conversation menu:
- Overview – This tab shows the Column impact analysis. In this case, median_income emerges as the primary factor influencing my model.
- Scoring – This tab provides model accuracy insights, including RMSE metrics.
- Advanced metrics – This tab displays the detailed Metrics table, Residuals and Error density for in-depth model evaluation.
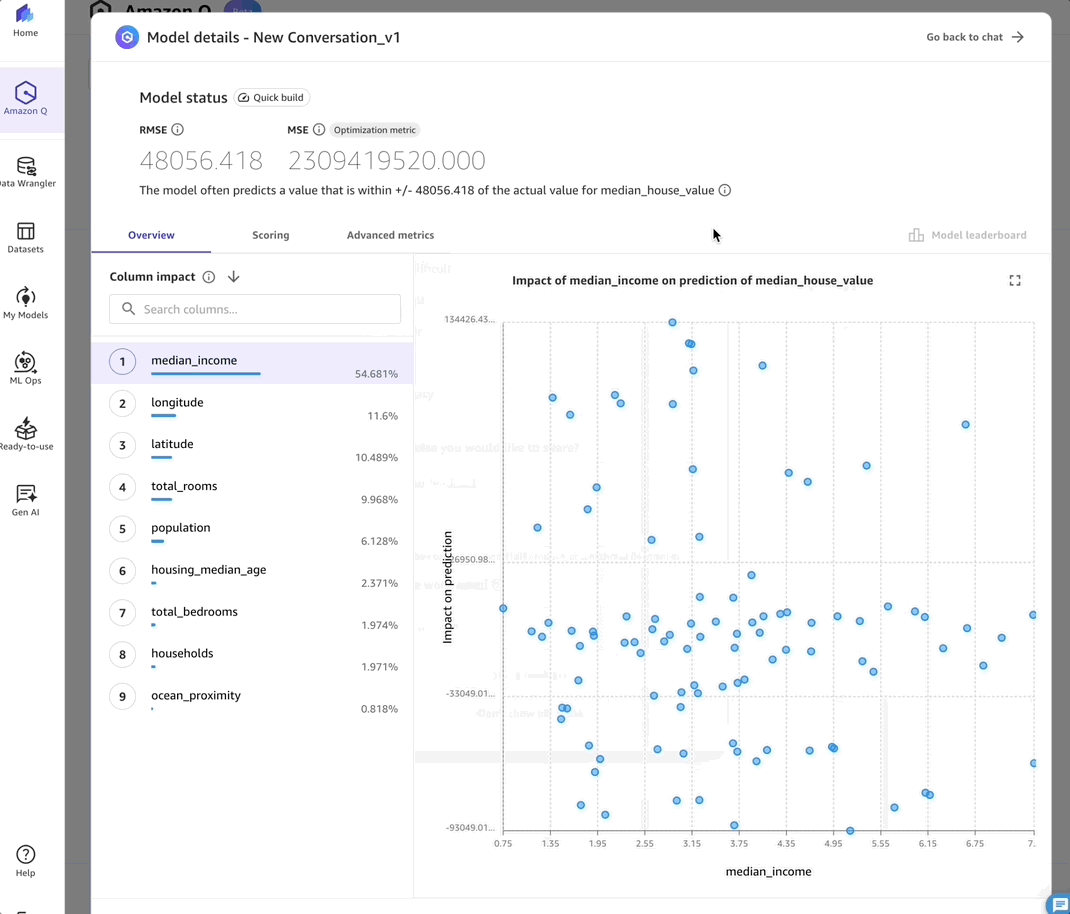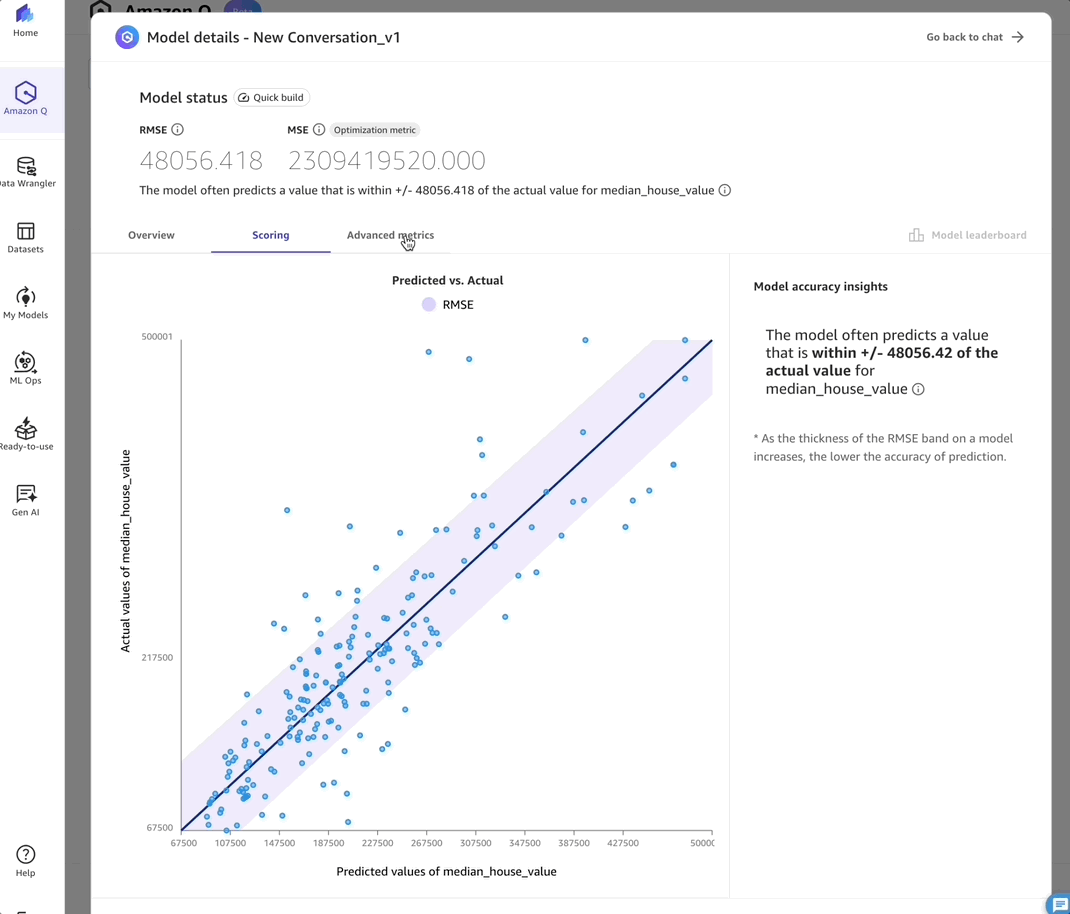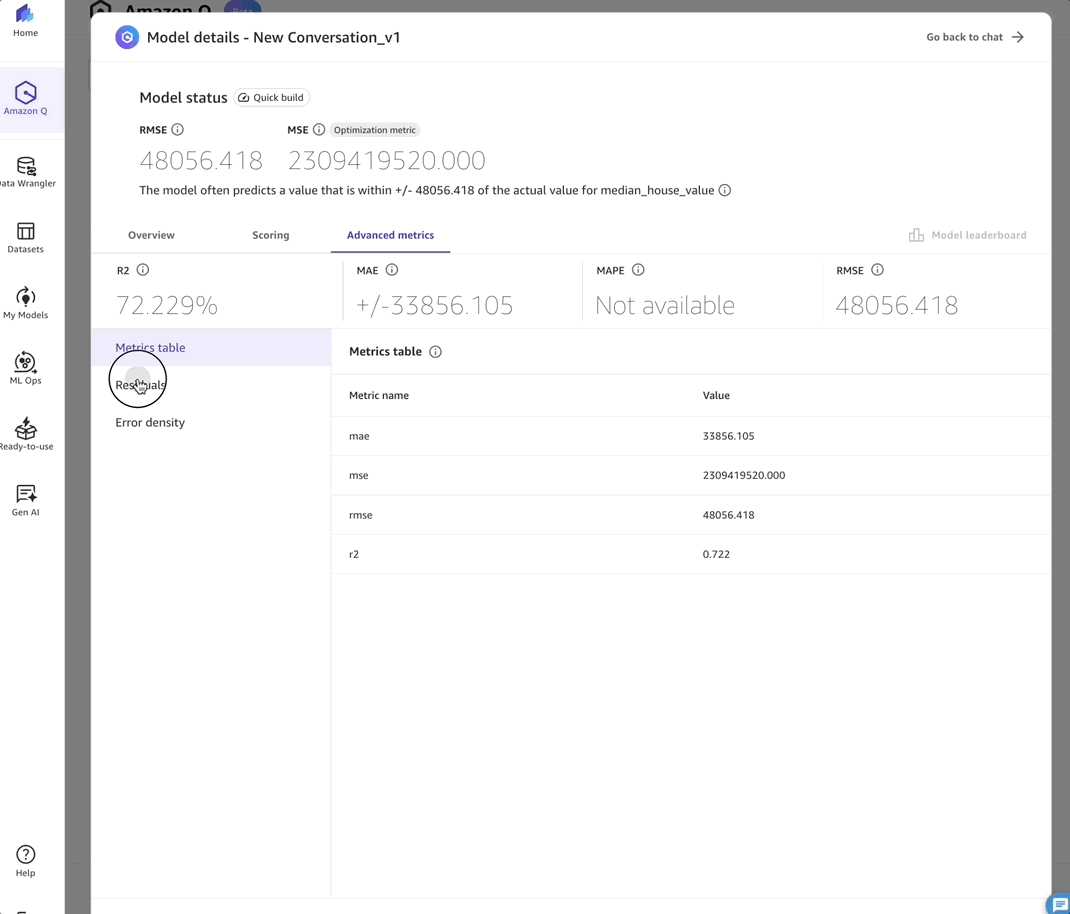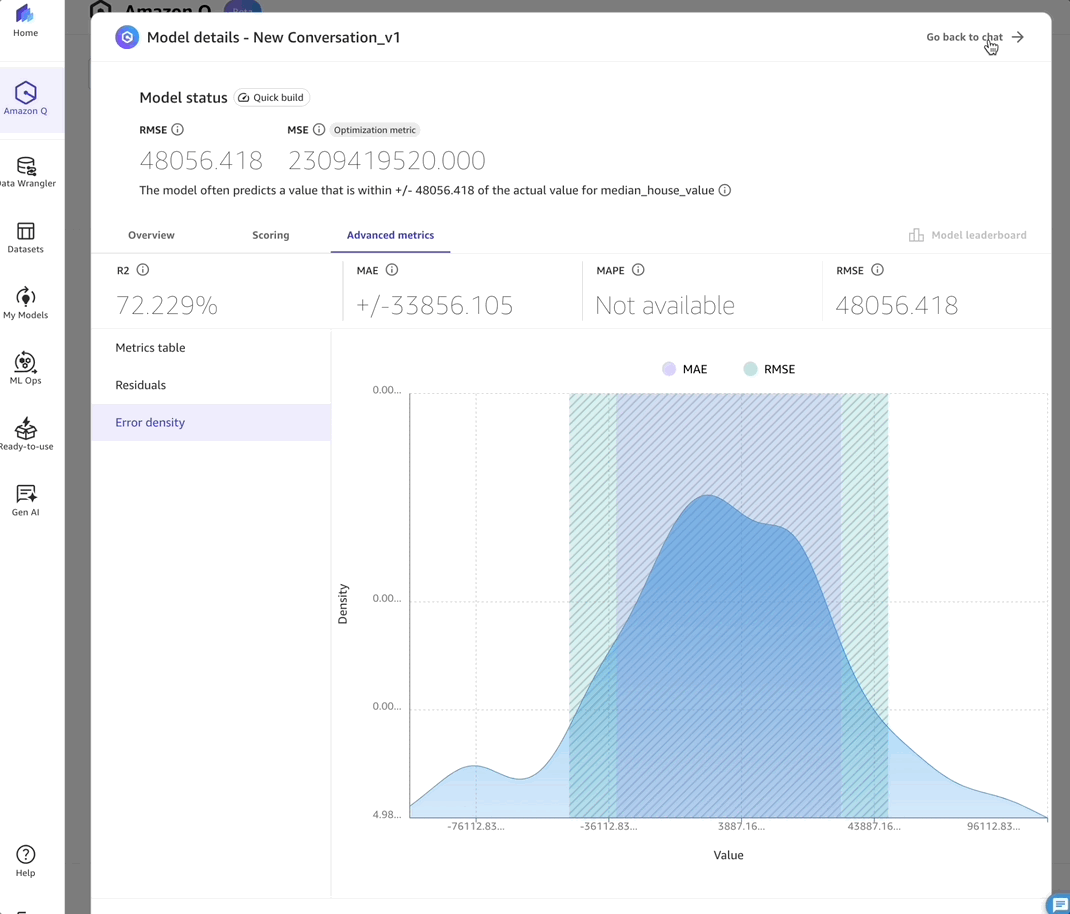
After reviewing these metrics and validating the model’s performance, I can move to the final stages of the ML workflow:
- Predictions – I can test my model using the Predictions tab to validate its real-world performance.
- Deployment – I can create an endpoint deployment to make my model available for production use.
This simplifies the deployment process, a step that traditionally requires significant DevOps knowledge, into a straightforward operation that business analysts can handle confidently.
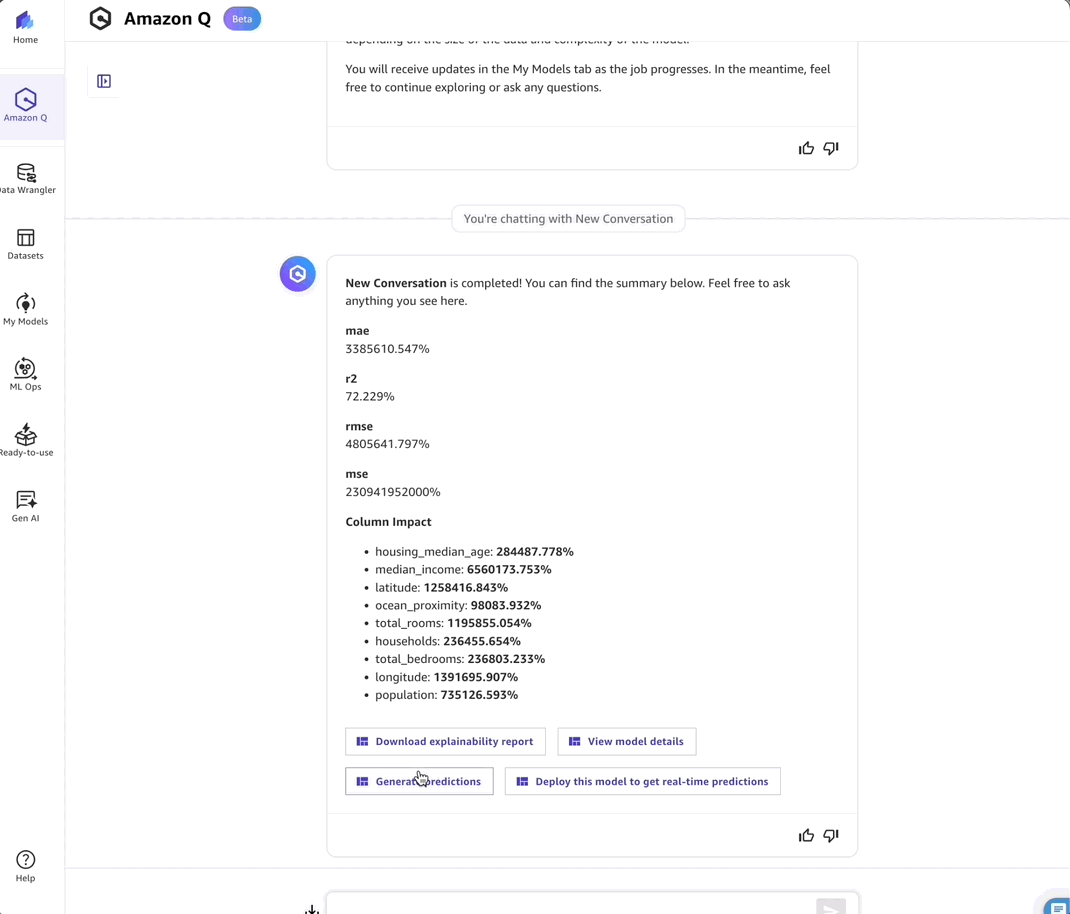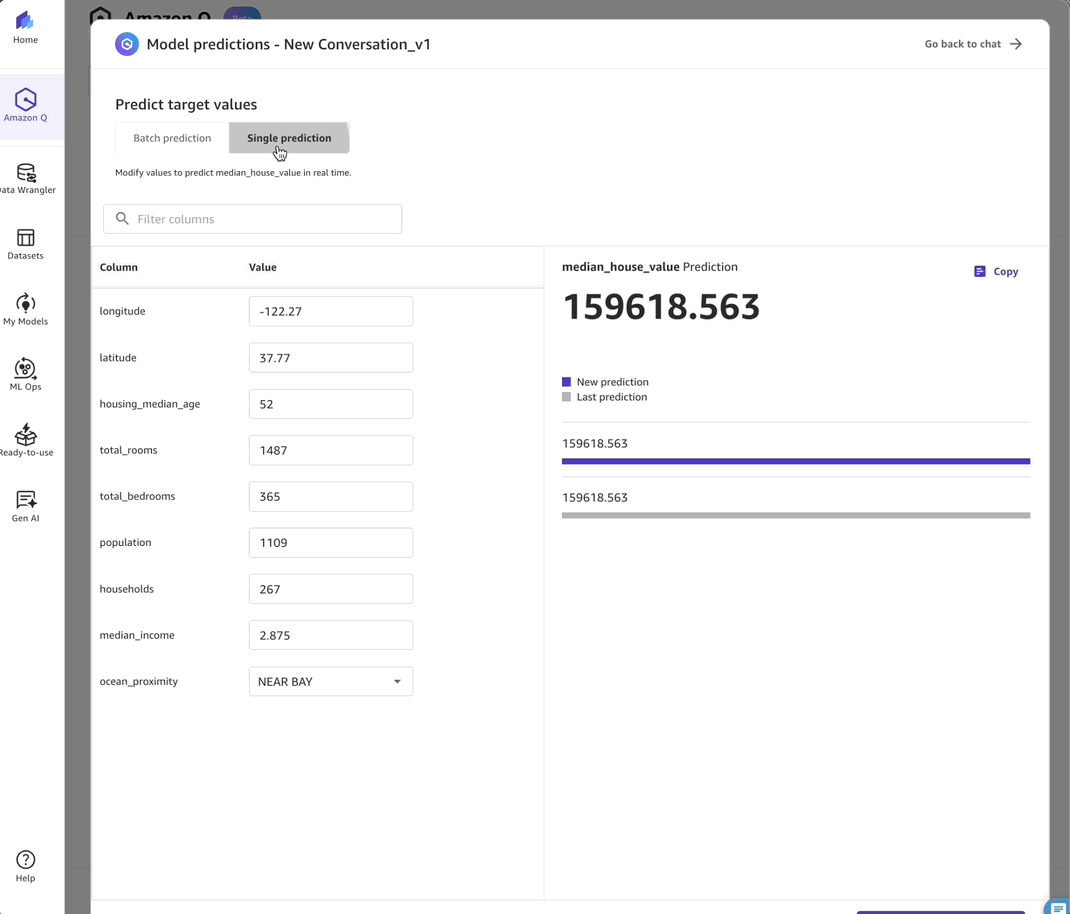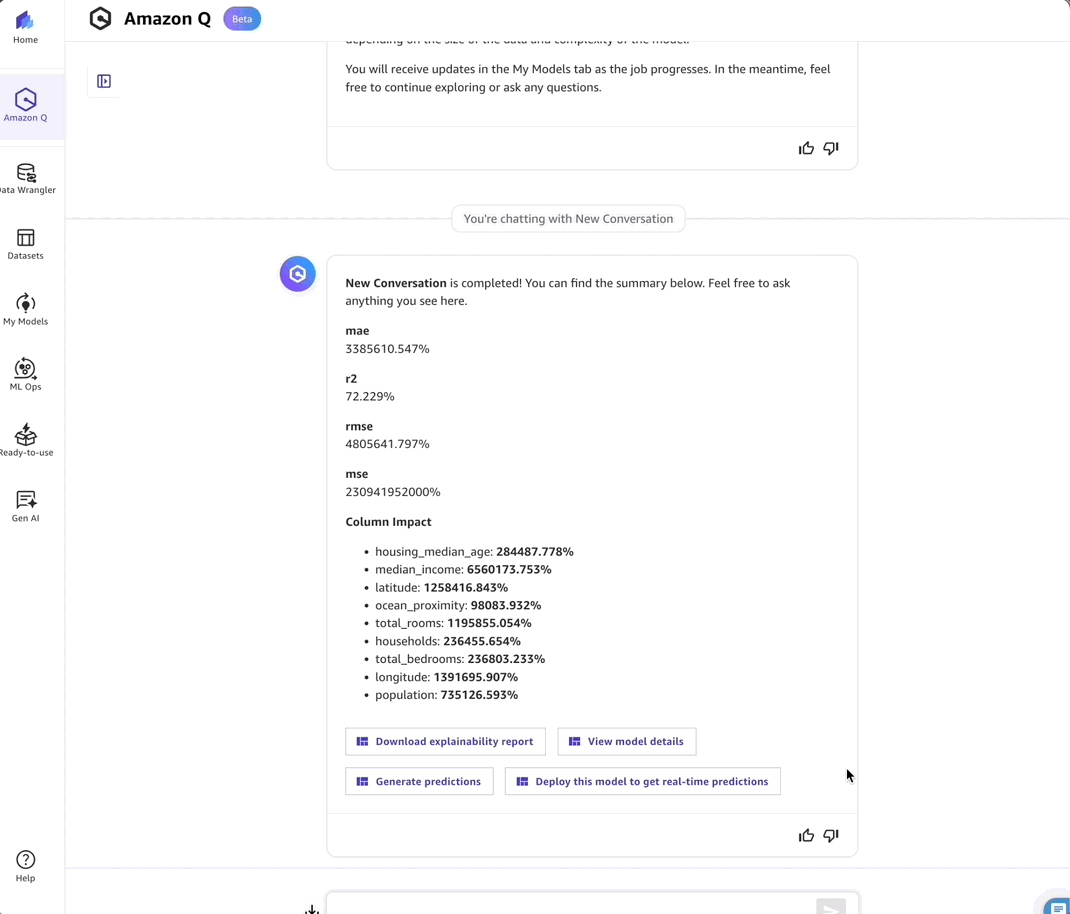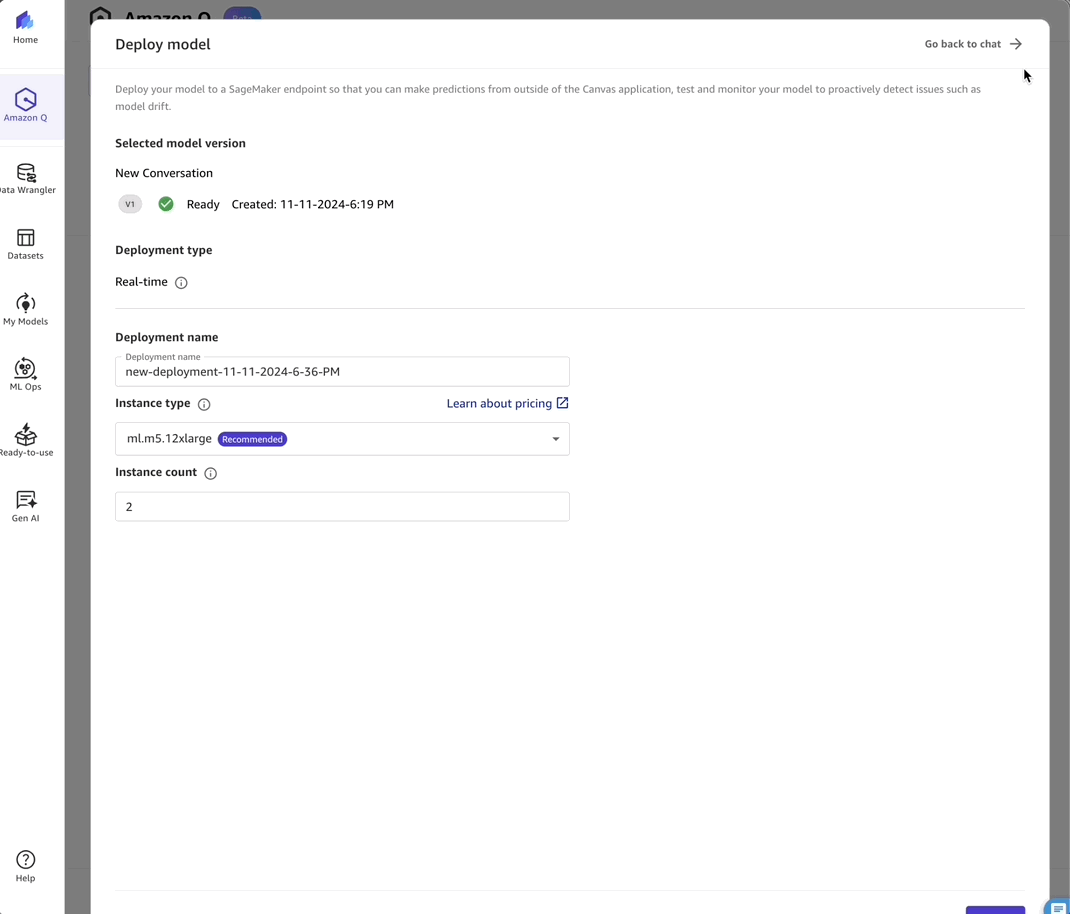
Things to know
Amazon Q Developer democratizes ML across organizations:
Empowering all skill levels with ML – Amazon Q Developer is now available in SageMaker Canvas, helping business analysts, marketing analysts, and data professionals who don’t have ML experience create solutions for business problems through a guided ML workflow. From data analysis and model selection to deployment, users can solve business problems using natural language, reducing dependence on ML experts such as data scientists and enabling organizations to innovate faster with reduced time to market.
Streamlining the ML workflow – With Amazon Q Developer available in SageMaker Canvas, users can prepare data, and build, analyze, and deploy ML models through a guided, transparent workflow. Amazon Q Developer provides advanced data preparation and AutoML capabilities that democratize ML, and allows non-ML experts to produce highly-accurate ML models.
Providing full visibility into the ML workflow – Amazon Q Developer provides full transparency by generating the underlying code and technical artifacts such as data transformation steps, model explainability, and accuracy measures. This allows cross-functional teams, including ML experts, to review, validate, and update the models as needed, facilitating collaboration in a secure environment.
Availability – Amazon Q Developer is now in preview release in Amazon SageMaker Canvas.
Pricing – Amazon Q Developer is now available in SageMaker Canvas at no additional cost to both Amazon Q Developer Pro Tier and Amazon Q Developer Free tier users. However, standard charges apply for resources such as SageMaker Canvas workspace instances and any resources used for building or deploying models. For detailed pricing information, visit the Amazon SageMaker Canvas Pricing.
To learn more about getting started visit the Amazon Q Developer product web page.
— Eli