 |
Today, I am excited to announce the general availability of Amazon Aurora PostgreSQL-Compatible Edition and Amazon DynamoDB zero-ETL integrations with Amazon Redshift. Zero-ETL integration seamlessly makes transactional or operational data available in Amazon Redshift, removing the need to build and manage complex data pipelines that perform extract, transform, and load (ETL) operations. It automates the replication of source data to Amazon Redshift, simultaneously updating source data for you to use in Amazon Redshift for analytics and machine learning (ML) capabilities to derive timely insights and respond effectively to critical, time-sensitive events.
Using these new zero-ETL integrations, you can run unified analytics on your data from different applications without having to build and manage different data pipelines to write data from multiple relational and non-relational data sources into a single data warehouse. In this post, I provide two step-by-step walkthroughs on how to get started with both Amazon Aurora PostgreSQL and Amazon DynamoDB zero-ETL integrations with Amazon Redshift.
To create a zero-ETL integration, you specify a source and Amazon Redshift as the target. The integration replicates data from the source to the target data warehouse, making it available in Amazon Redshift seamlessly, and monitors the pipeline’s health.
Let’s explore how these new integrations work. In this post, you will learn how to create zero-ETL integrations to replicate data from different source databases (Aurora PostgreSQL and DynamoDB) to the same Amazon Redshift cluster. You will also learn how to select multiple tables or databases from Aurora PostgreSQL source databases to replicate data to the same Amazon Redshift cluster. You will observe how zero-ETL integrations provide flexibility without the operational burden of building and managing multiple ETL pipelines.
Getting started with Aurora PostgreSQL zero-ETL integration with Amazon Redshift
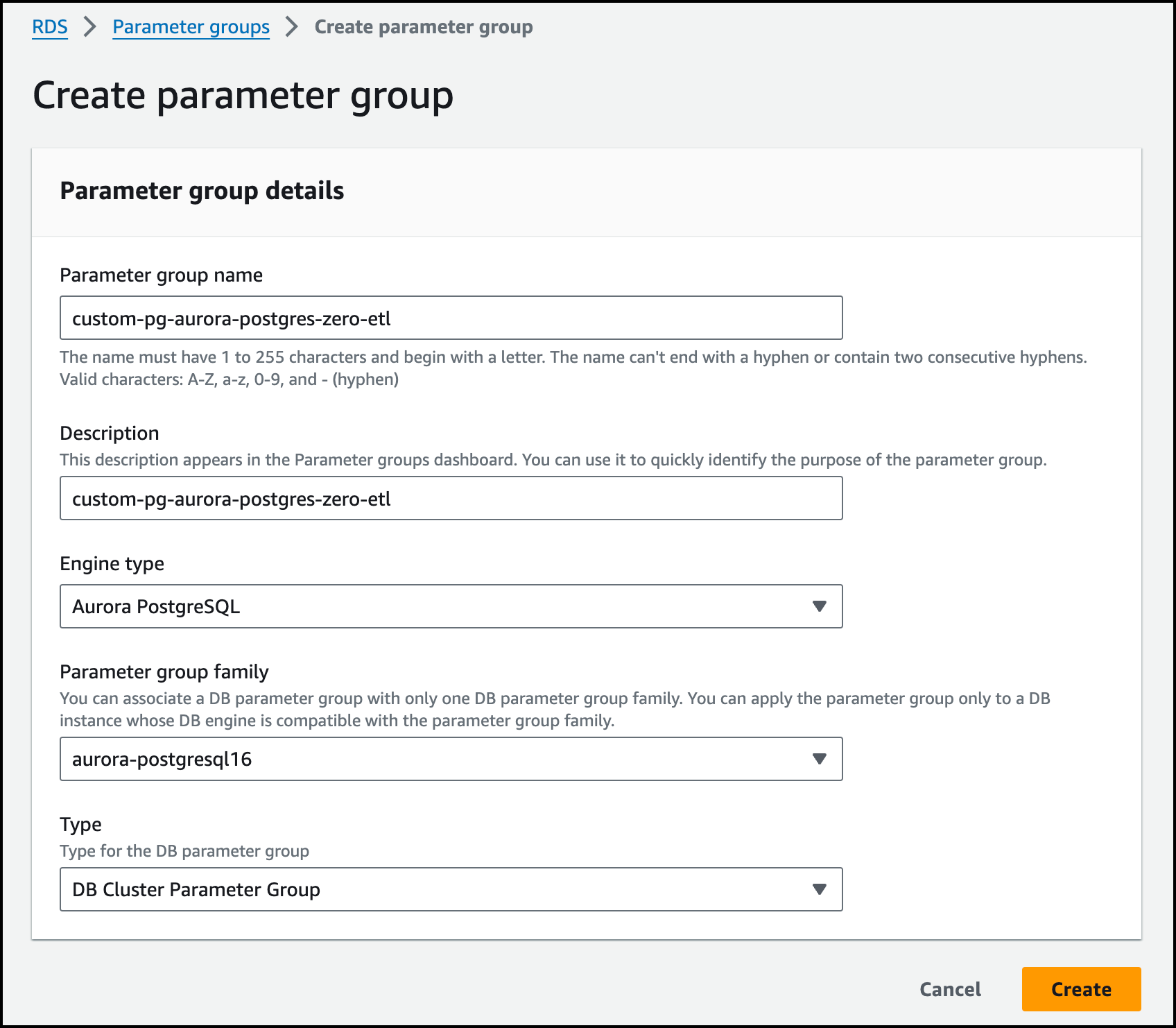
Before creating a database, I create a custom cluster parameter group because Aurora PostgreSQL zero-ETL integration with Amazon Redshift requires specific values for the Aurora DB cluster parameters. In the Amazon RDS console, I go to Parameter groups in the navigation pane. I choose Create parameter group.
I enter custom-pg-aurora-postgres-zero-etl for Parameter group name and Description. I choose Aurora PostgreSQL for Engine type and aurora-postgresql16 for Parameter group family (zero-ETL integration works with PostgreSQL 16.4 or above versions). Finally, I choose DB Cluster Parameter Group for Type and choose Create.
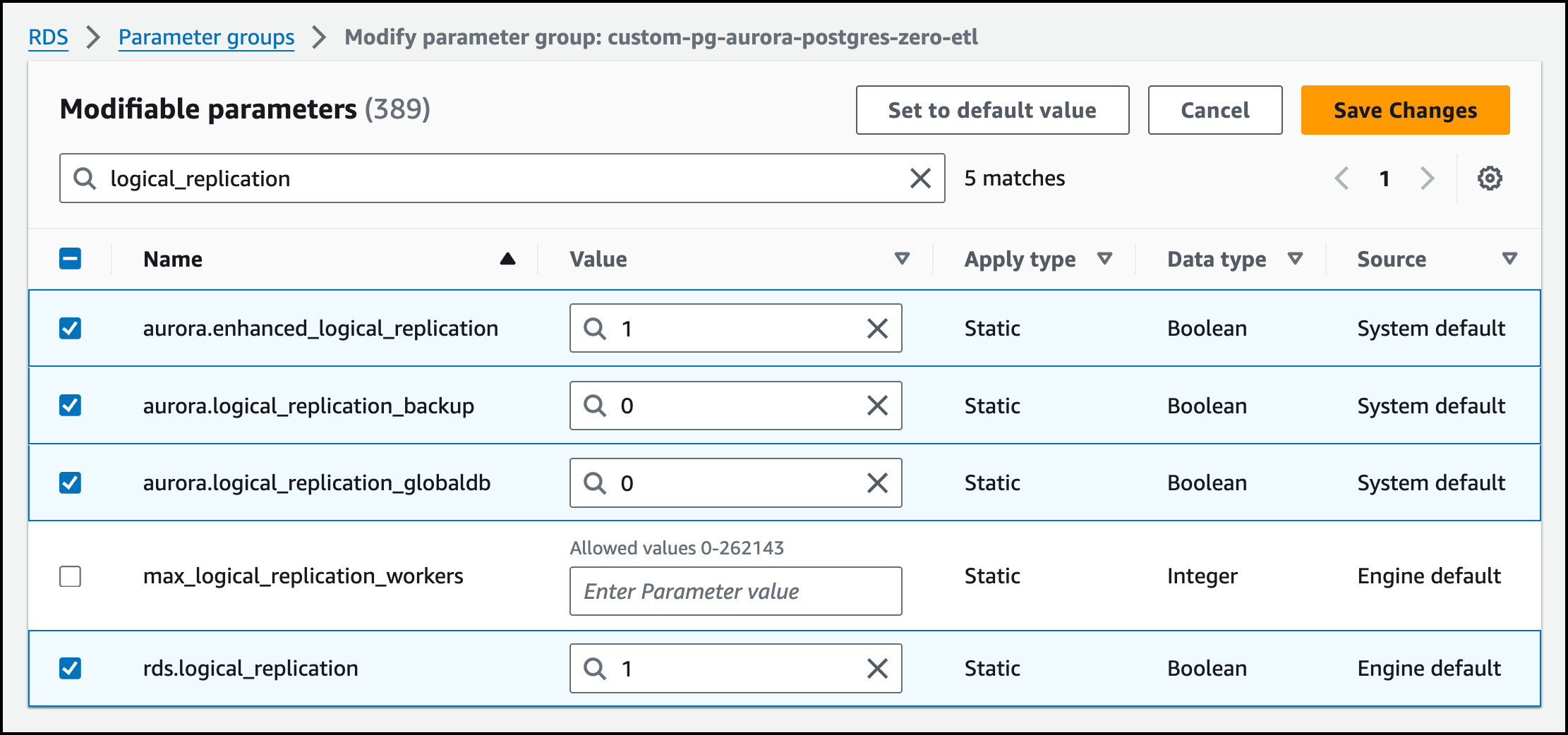
Next, I edit the newly created cluster parameter group by choosing it on the Parameter groups page. I choose Actions and then choose Edit. I set the following cluster parameter settings:
rds.logical_replication=1aurora.enhanced_logical_replication=1aurora.logical_replication_backup=0aurora.logical_replication_globaldb=0
I choose Save Changes.
Next, I create an Aurora PostgreSQL database. When creating the database, you can set the configurations according to your needs. Remember to choose Aurora PostgreSQL (compatible with PostgreSQL 16.4 or above) from Available versions and the custom cluster parameter group (custom-pg-aurora-postgres-zero-etl in this case) for DB cluster parameter group in the Additional configuration section.
After the database becomes available, I connect to the Aurora PostgreSQL cluster, create a database named books, create a table named book_catalog in the default schema for this database and insert sample data to use with zero-ETL integration.

To get started with zero-ETL integration, I use an existing Amazon Redshift data warehouse. To create and manage Amazon Redshift resources, visit the Amazon Redshift Getting Started Guide.
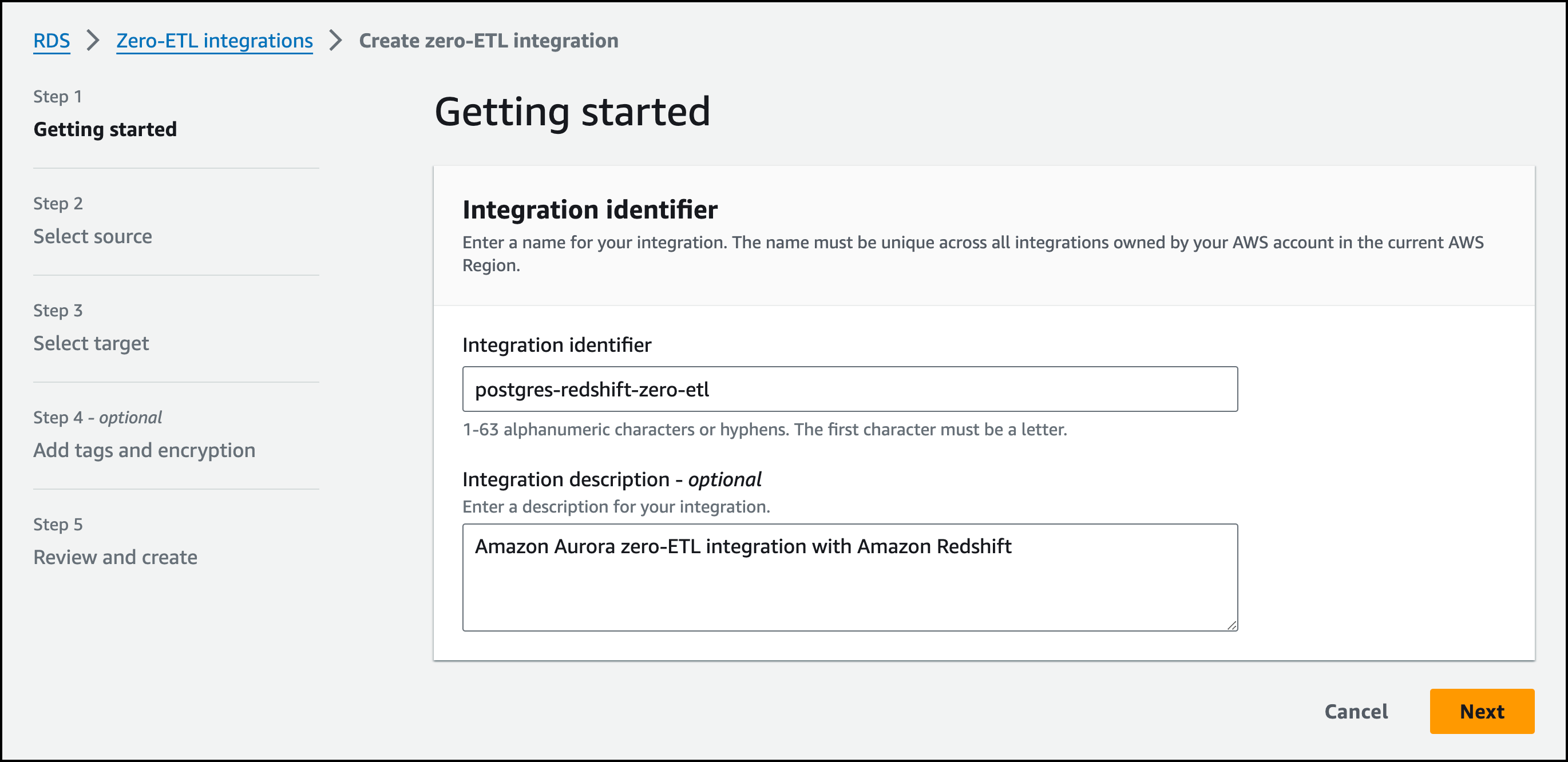
In the Amazon RDS console, I go to the Zero-ETL integrations tab in the navigation pane and choose Create zero-ETL integration. I enter postgres-redshift-zero-etl for Integration identifier and Amazon Aurora zero-ETL integration with Amazon Redshift for Integration description. I choose Next.
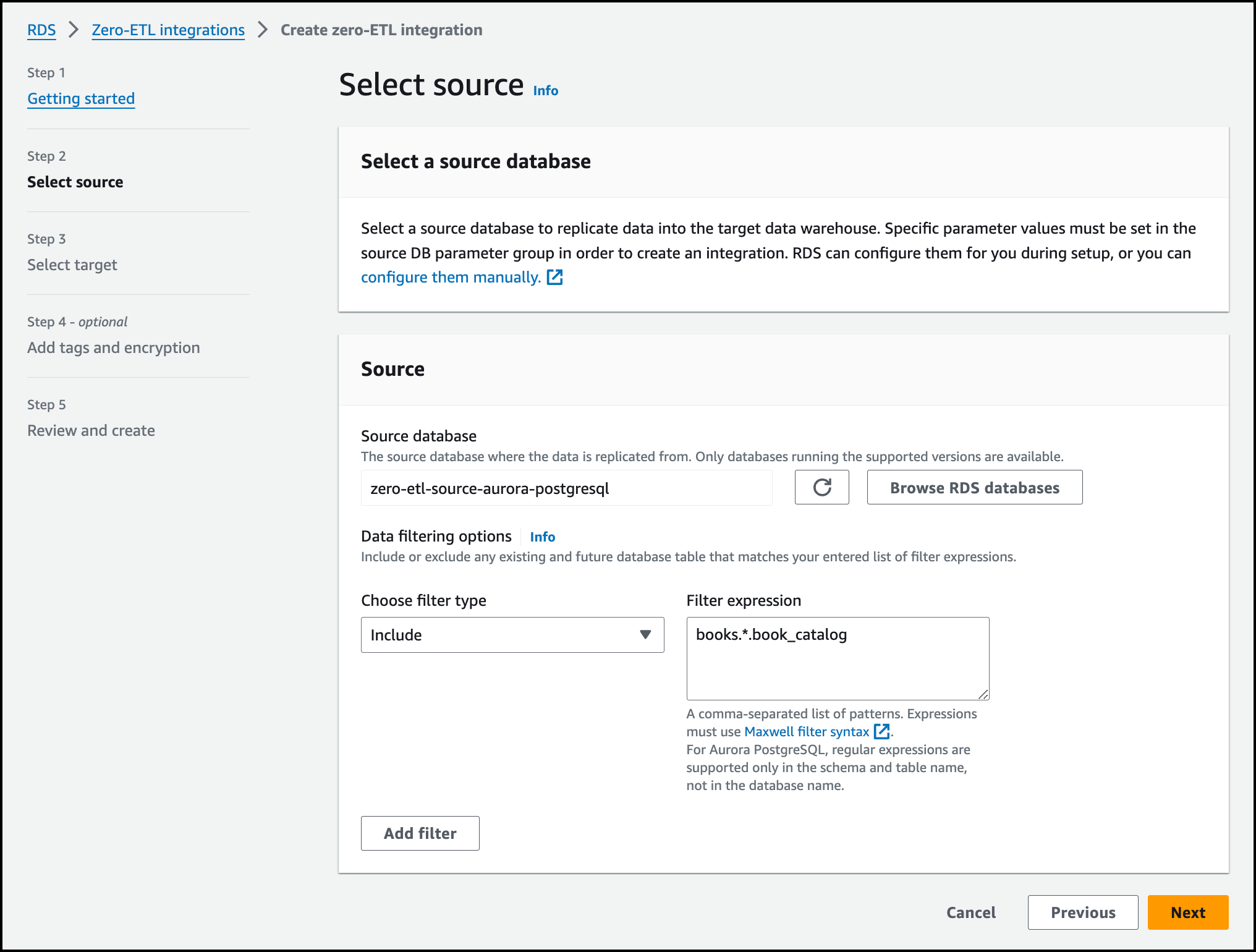
On the next page, I choose Browse RDS databases to select the source database. For the Data filtering options, I use database.schema.table pattern. I include my table called book_catalog in Aurora PostgreSQL books database. The * in filters will replicate all book_catalog tables in all schemas within books database. I choose Include as filter type and enter books.*.book_catalog into the Filter expression field. I choose Next.
On the next page, I choose Browse Redshift data warehouses and select the existing Amazon Redshift data warehouse as the target. I must specify authorized principals and integration source on the target to enable Amazon Aurora to replicate into the data warehouse and enable case sensitivity. Amazon RDS can complete these steps for me during setup, or I can configure them manually in Amazon Redshift. For this demo, I choose Fix it for me and choose Next.
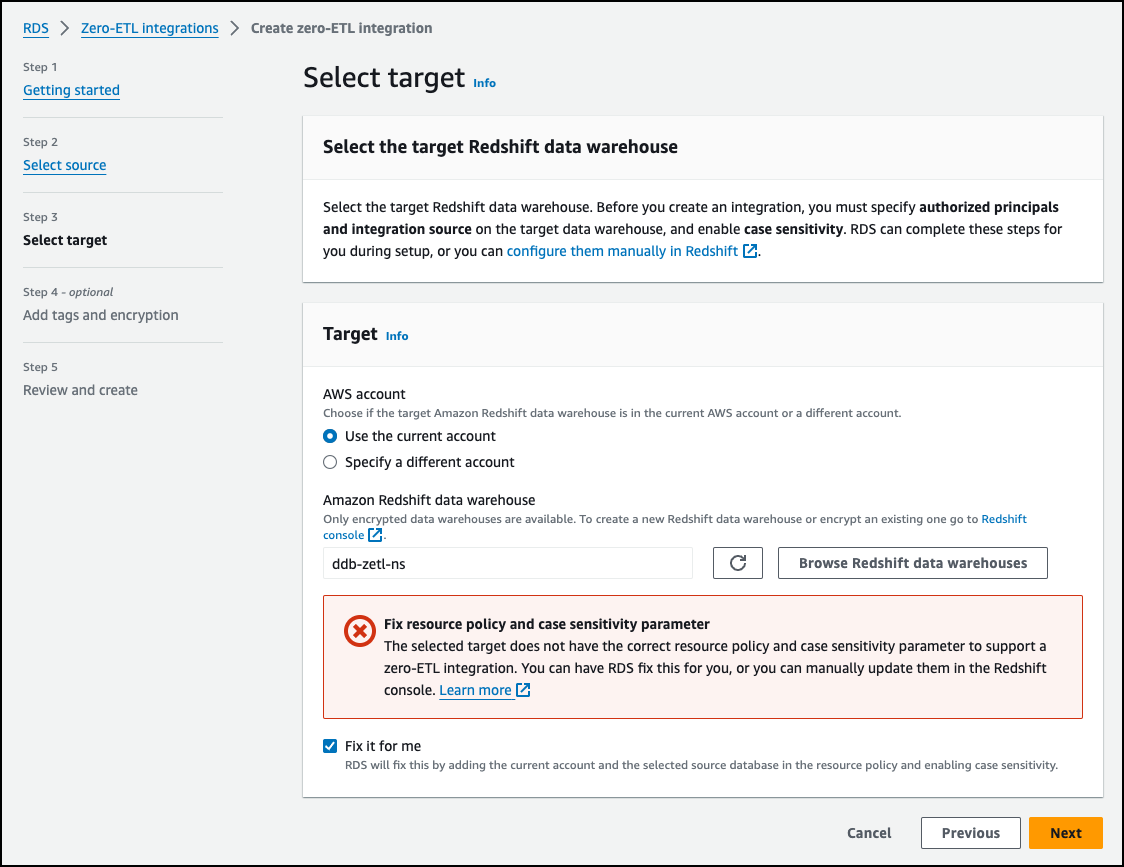
After the case sensitivity parameter and the resource policy for data warehouse are fixed, I choose Next on the next Add tags and encryption page. After I review the configuration, I choose Create zero-ETL integration.
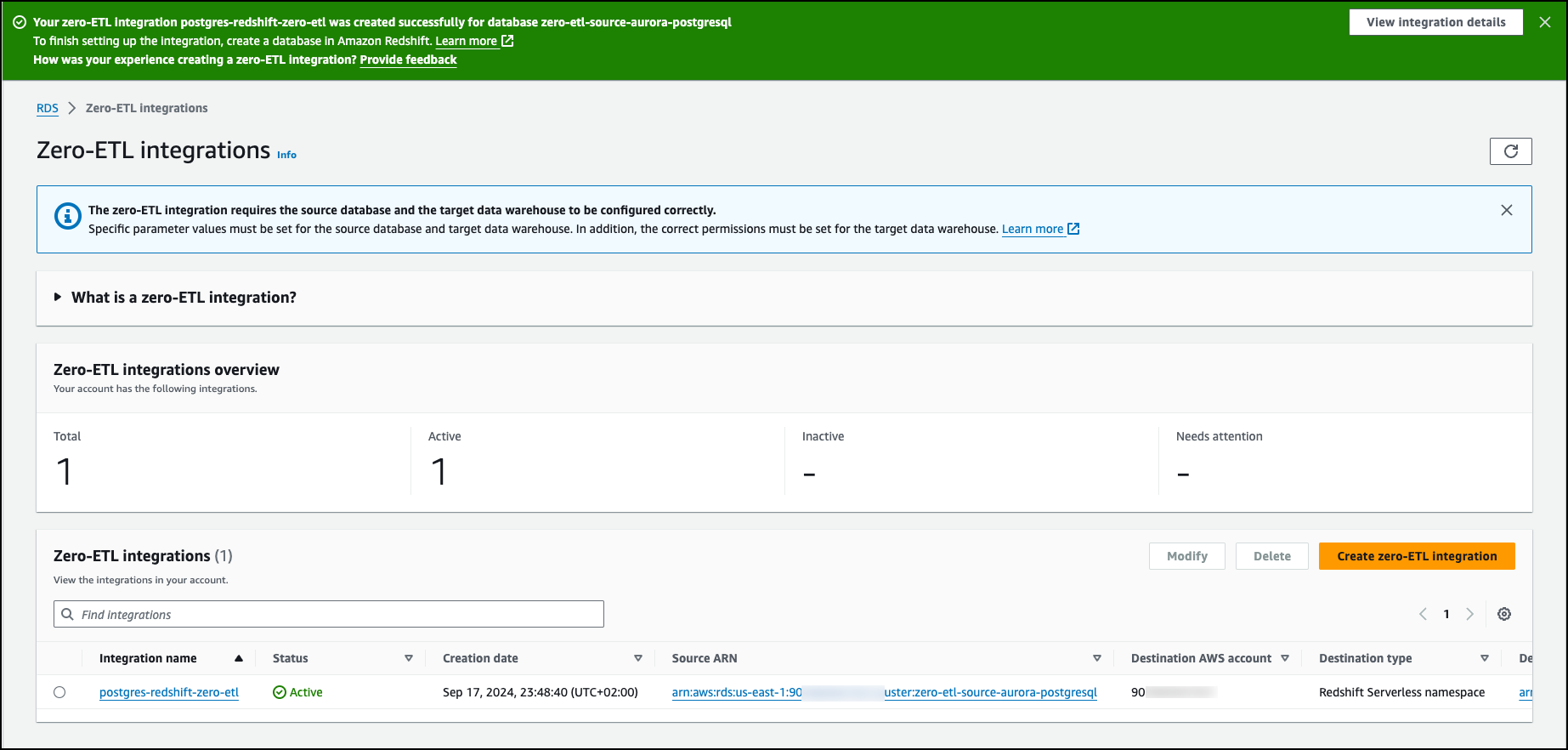
After the integration succeeded, I choose the integration name to check the details.
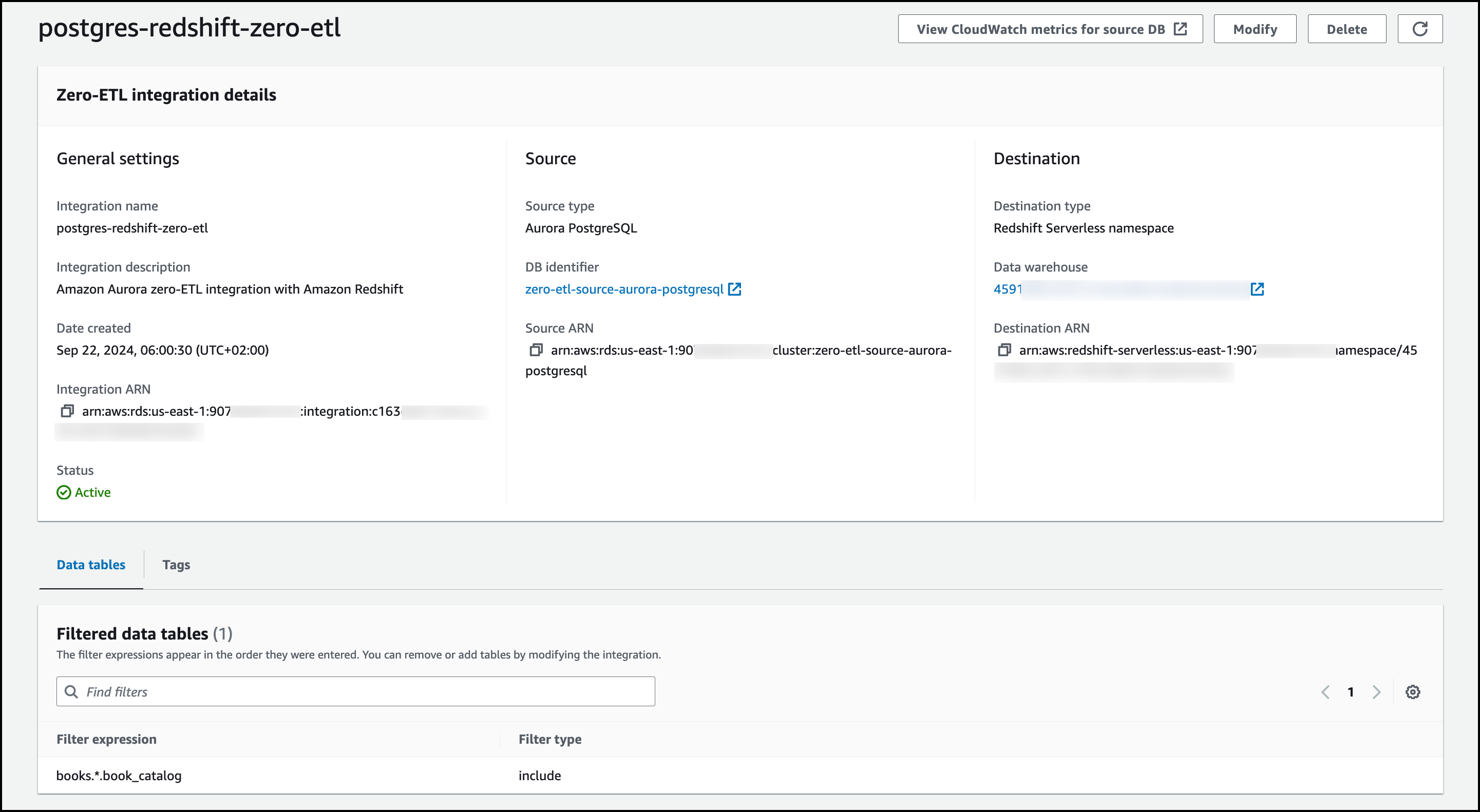
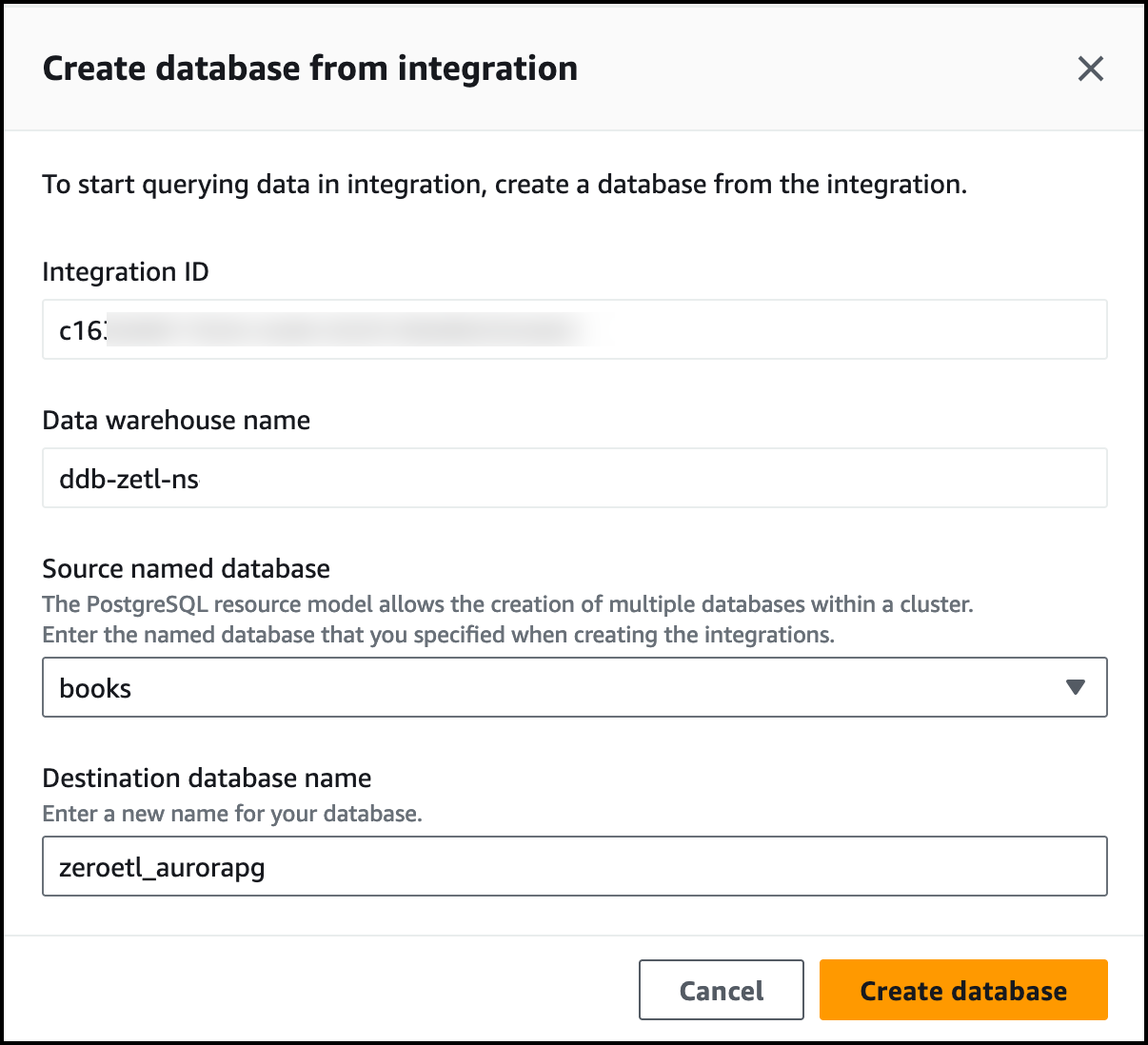
Now, I need to create a database from integration to finish setting up. I go to the Amazon Redshift console, choose Zero-ETL integrations in the navigation pane and select the Aurora PostgreSQL integration I just created. I choose Create database from integration.
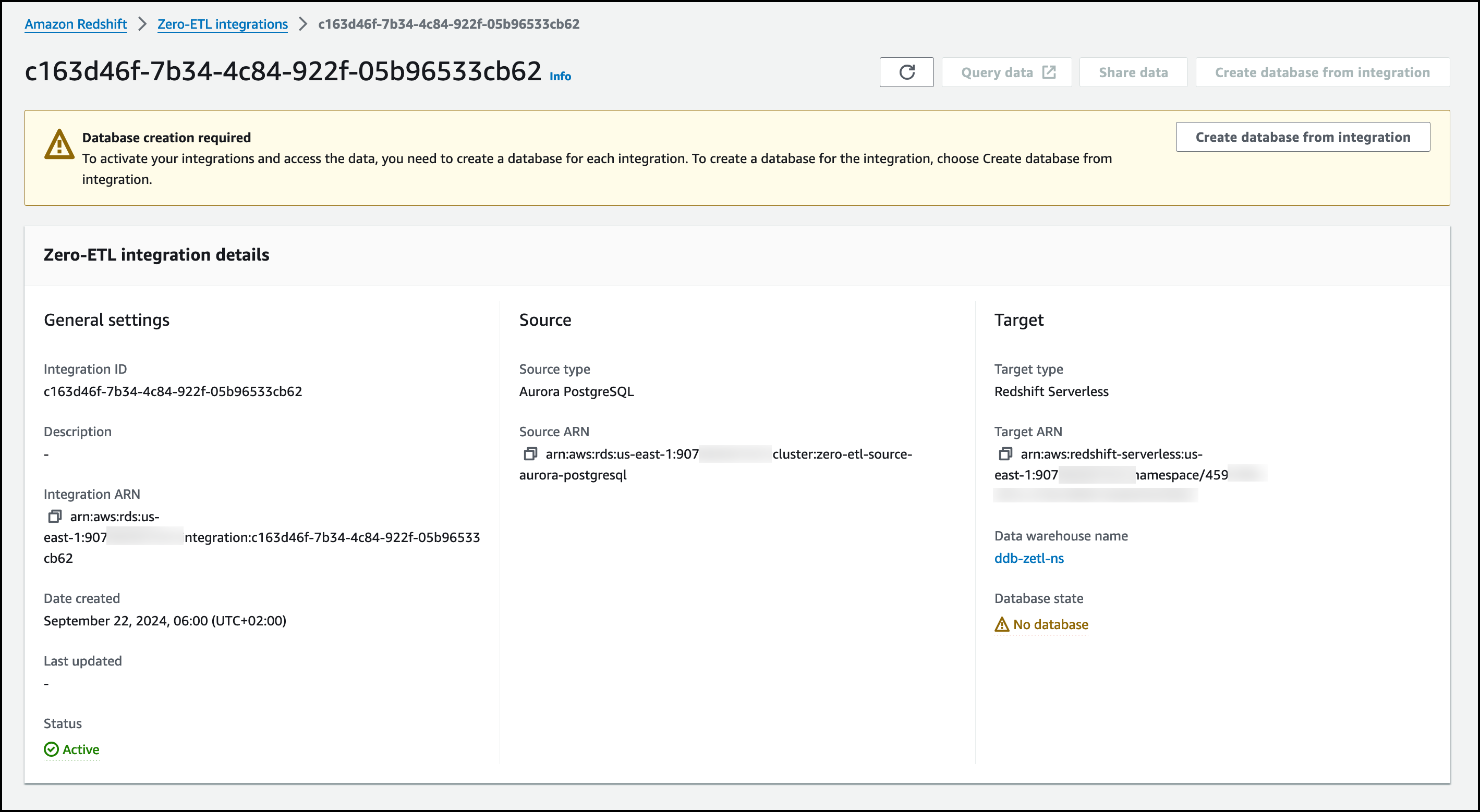
I choose books as Source named database and I enter zeroetl_aurorapg as the Destination database name. I choose Create database.
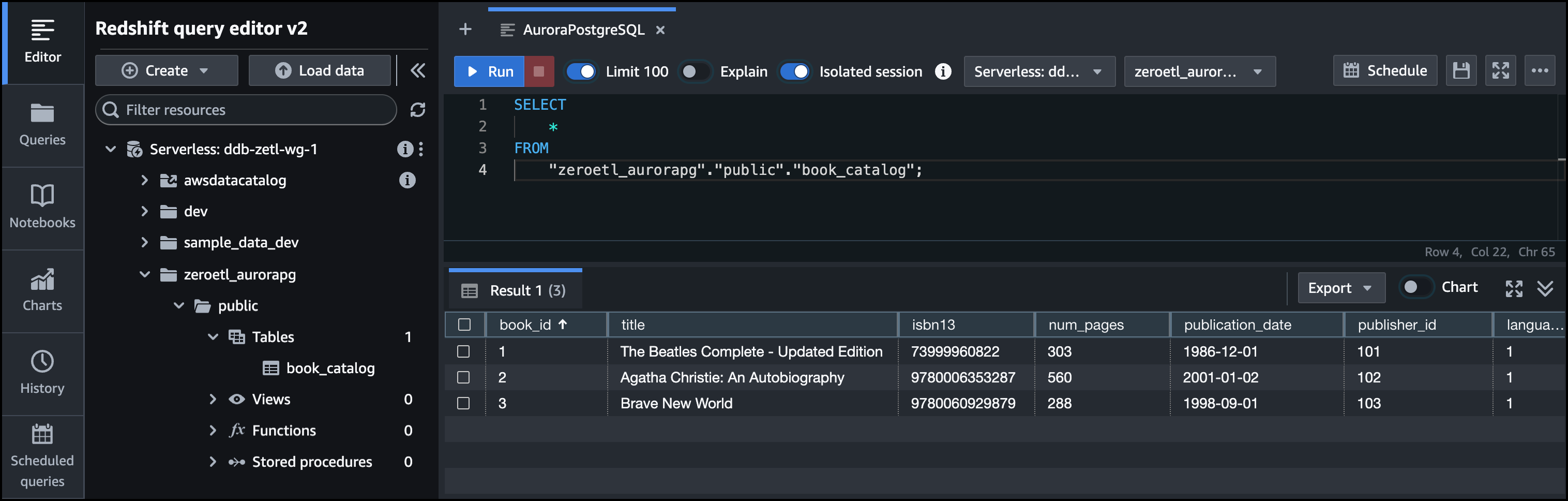
After the database is created, I return to the Aurora PostgreSQL integration page. On this page, I choose Query data to connect to the Amazon Redshift data warehouse to observe if the data is replicated. When I run a select query in the zeroetl_aurorapg database, I see that the data in book_catalog table is replicated to Amazon Redshift successfully.
As I said in the beginning, you can select multiple tables or databases from the Aurora PostgreSQL source database to replicate the data to the same Amazon Redshift cluster. To add another database to the same zero-ETL integration, all I have to do is to add another filter to the Data filtering options in the form of database.schema.table, replacing the database part with the database name I want to replicate. For this demo, I will select multiple tables to be replicated to the same data warehouse. I create another table named publisher in the Aurora PostgreSQL cluster and insert sample data to it.

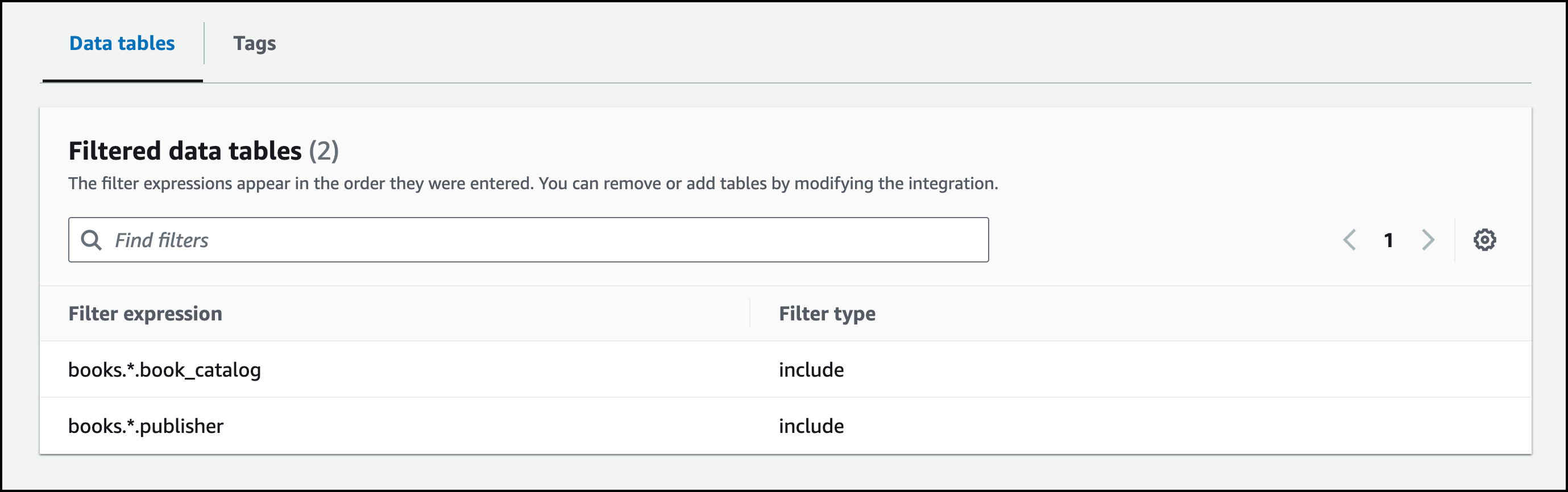
I edit the Data filtering options to include publisher table for replication. To do this, I go to the postgres-redshift-zero-etl details page and choose Modify. I append books.*.publisher using comma in the Filter expression field. I choose Continue. I review the changes and choose Save changes. I observe that the Filtered data tables section on the integration details page has now 2 tables included for replication.
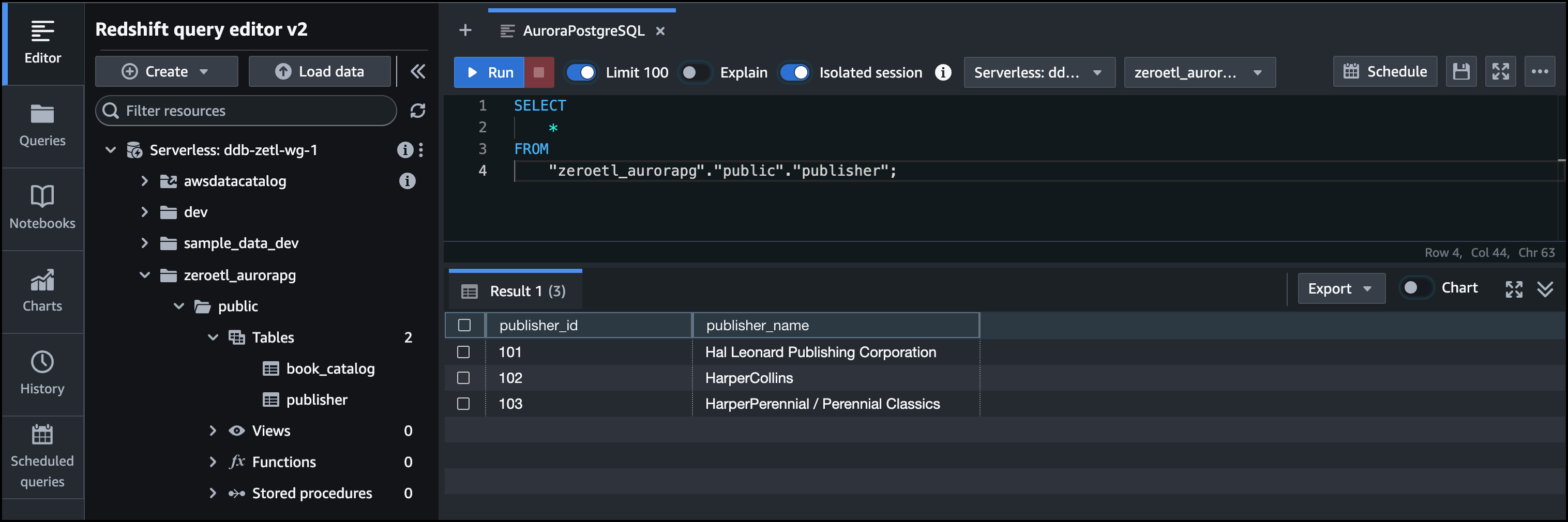
When I switch to the Amazon Redshift Query editor and refresh the tables, I can see that the new publisher table and its records are replicated to the data warehouse.
Now that I completed the Aurora PostgreSQL zero-ETL integration with Amazon Redshift, let’s create a DynamoDB zero-ETL integration with the same data warehouse.
Getting started with DynamoDB zero-ETL integration with Amazon Redshift
In this part, I proceed to create an Amazon DynamoDB zero-ETL integration using an existing Amazon DynamoDB table named Book_Catalog. The table has 2 items in it:
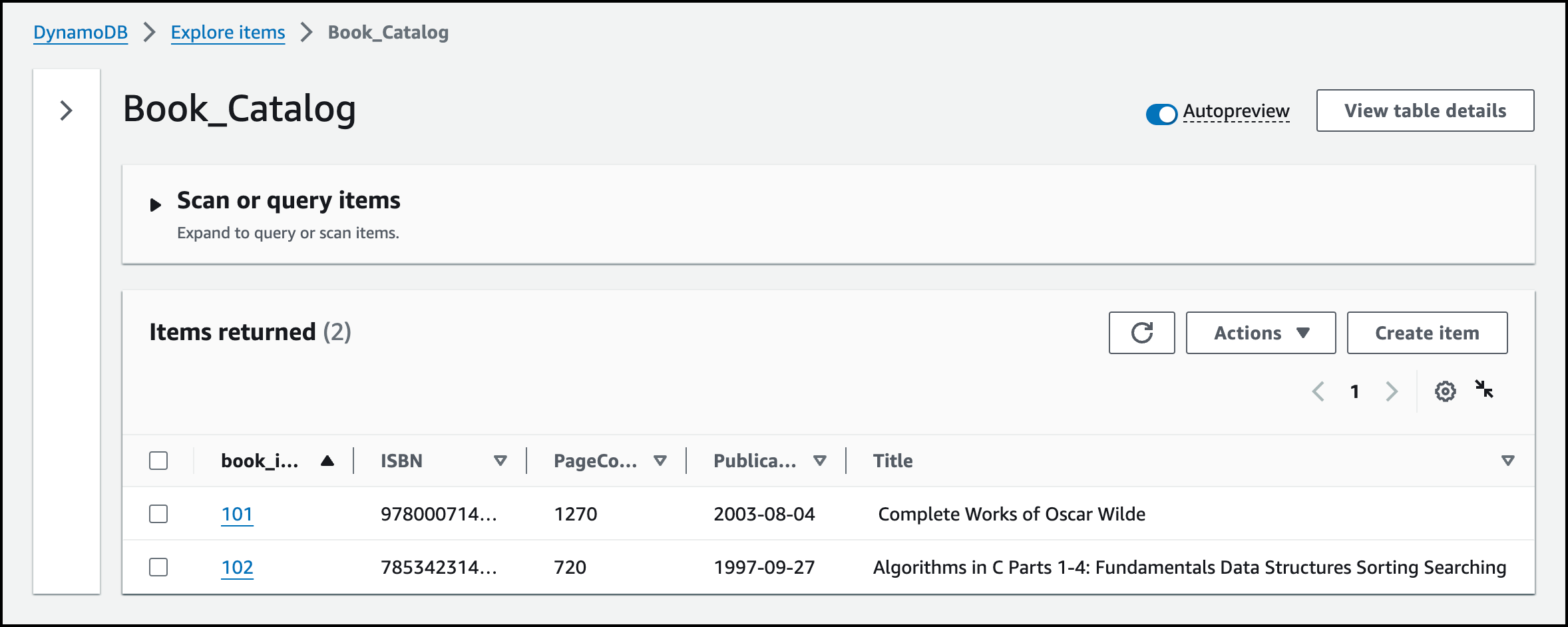
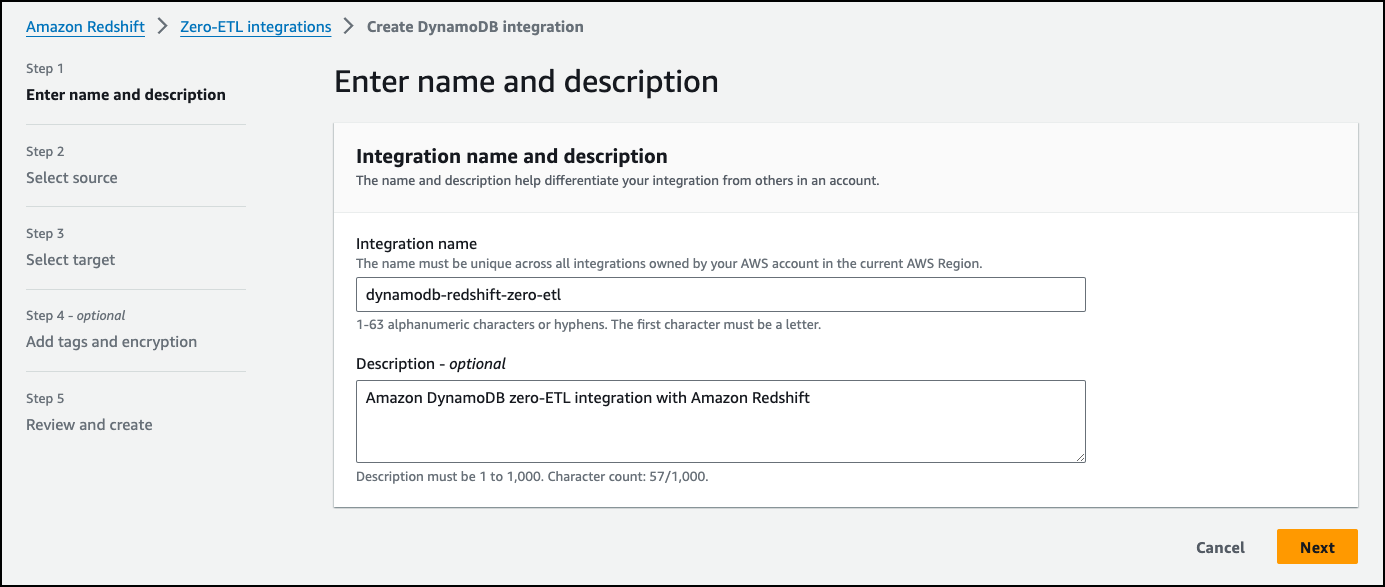
I go to the Amazon Redshift console and choose Zero-ETL integrations in the navigation pane. Then, I choose the arrow next to the Create zero-ETL integration and choose Create DynamoDB integration. I enter dynamodb-redshift-zero-etl for Integration name and Amazon DynamoDB zero-ETL integration with Amazon Redshift for Description. I choose Next.
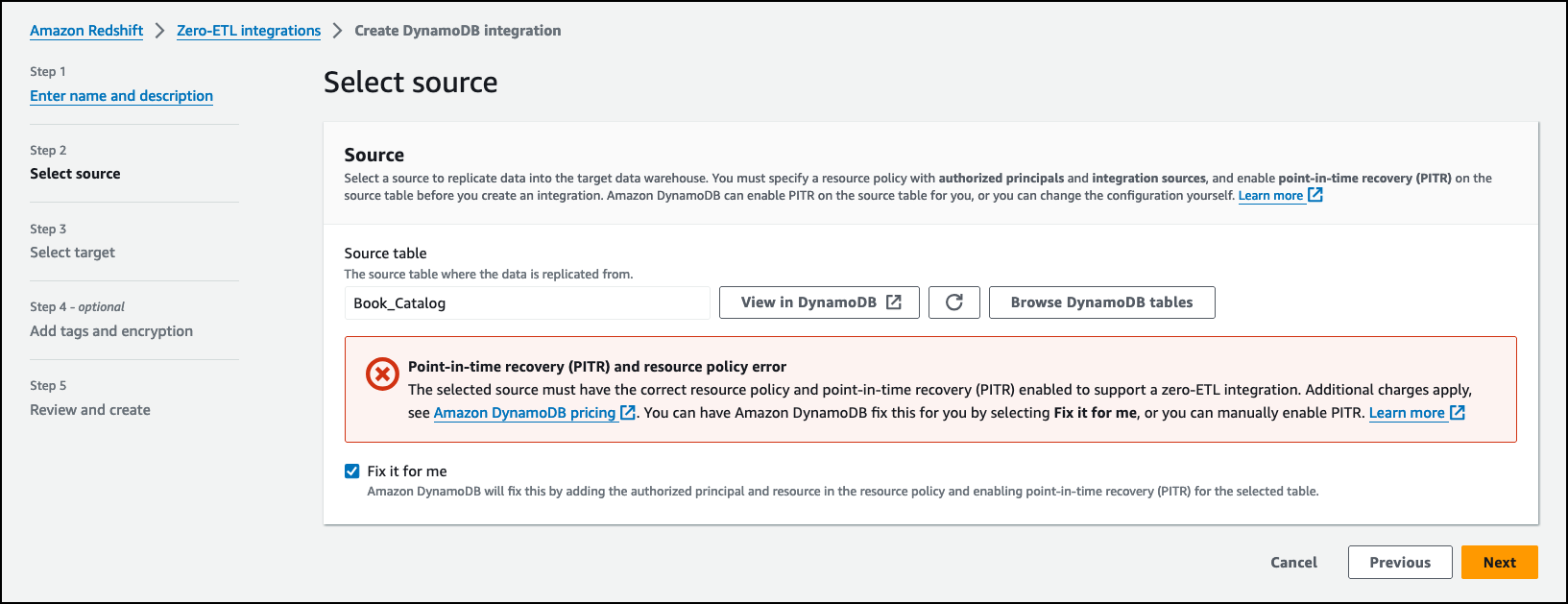
On the next page, I choose Browse DynamoDB tables and select the Book_Catalog table. I must specify a resource policy with authorized principals and integration sources, and enable point-in-time recovery (PITR) on the source table before I create an integration. Amazon DynamoDB can do it for me, or I can change the configuration manually. I choose Fix it for me to automatically apply the required resource policies for the integration and enable PITR on the DynamoDB table. I choose Next.
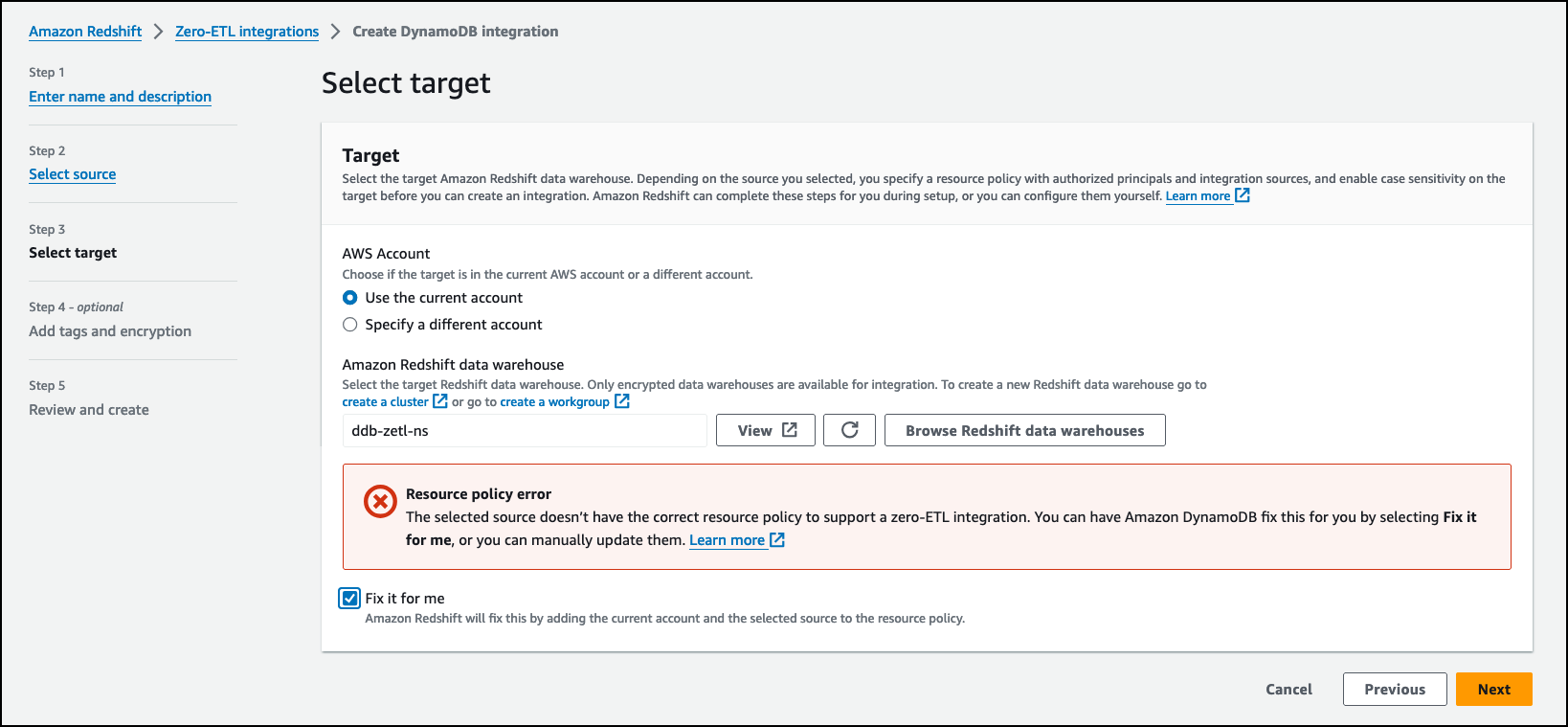
Then, I choose my existing Amazon Redshift Serverless data warehouse as the target and choose Next.
I choose Next again in the Add tags and encryption page and choose Create DynamoDB integration in the Review and create page.
Now, I need to create a database from integration to finish setting up just like I did with Aurora PostgreSQL zero-ETL integration. In the Amazon Redshift console, I choose the DynamoDB integration and I choose Create database from integration. In the popup screen, I enter zeroetl_dynamodb as the Destination database name and choose Create database.
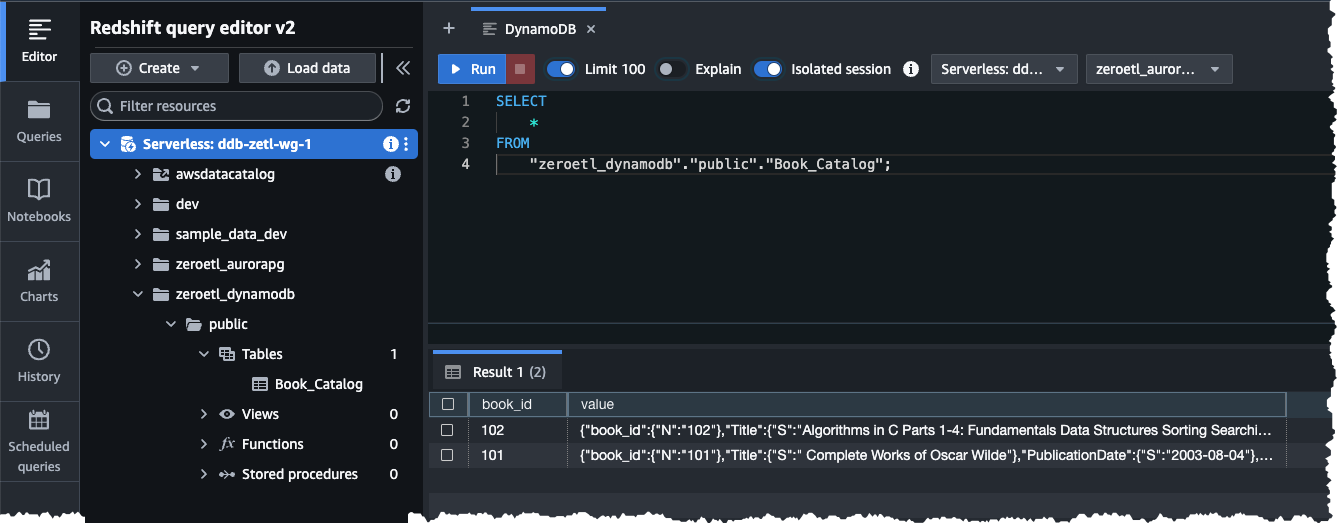
After the database is created, I go to the Amazon Redshift Zero-ETL integrations page and choose the DynamoDB integration I created. On this page, I choose Query data to connect to the Amazon Redshift data warehouse to observe if the data from DynamoDB Book_Catalog table is replicated. When I run a select query in the zeroetl_dynamodb database, I see that the data is replicated to Amazon Redshift successfully. Note that the data from DynamoDB is replicated in SUPER datatype column and can be accessed using PartiQL sql.
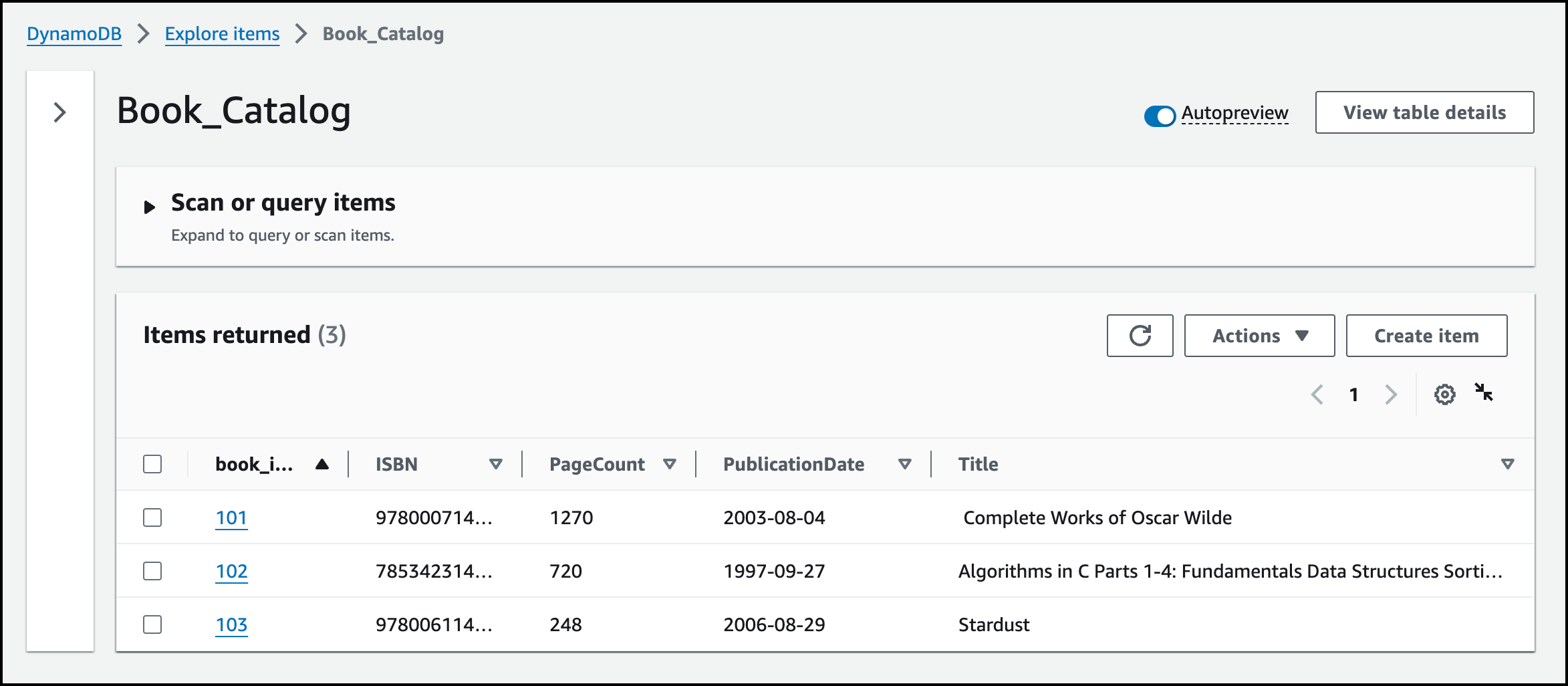
I insert another entry to the DynamoDB Book_Catalog table.
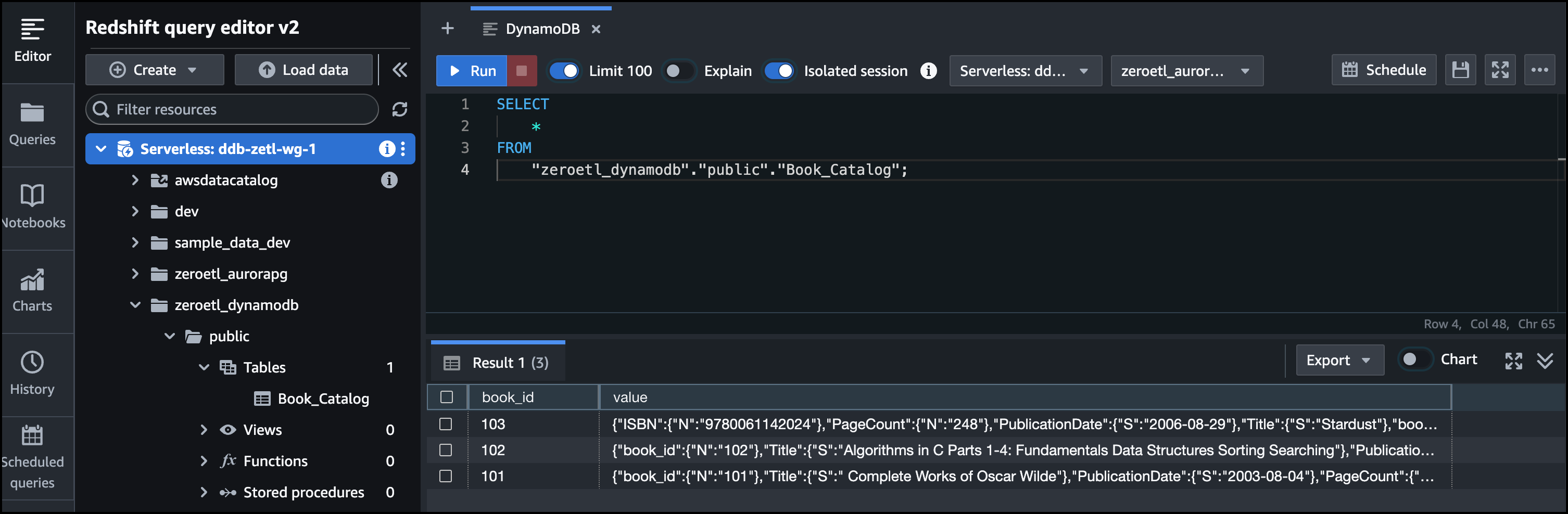
When I switch to the Amazon Redshift Query editor and refresh the select query, I can see that the new record is replicated to the data warehouse.
Zero-ETL integrations between Aurora PostgreSQL and DynamoDB with Amazon Redshift help you unify data from multiple database clusters and unlock insights in your data warehouse. Amazon Redshift allows cross-database queries and materialized views based off the multiple tables, giving you the opportunity to consolidate and simplify your analytics assets, improve operational efficiency, and optimize cost. You no longer have to worry about setting up and managing complex ETL pipelines.
Now available
Aurora PostgreSQL zero-ETL integration with Amazon Redshift is now available in US East (N. Virginia), US East (Ohio), US West (Oregon), Asia Pacific (Hong Kong), Asia Pacific (Mumbai), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Europe (Frankfurt), Europe (Ireland), and Europe (Stockholm) AWS Regions.
Amazon DynamoDB zero-ETL integration with Amazon Redshift is now available in all commercial, China and GovCloud AWS Regions.
For pricing information, visit the Amazon Aurora and Amazon DynamoDB pricing pages.
To get started with this feature, visit Working with Aurora zero-ETL integrations with Amazon Redshift and Amazon Redshift Zero-ETL integrations documentation.
— Esra

