|
During AWS re:Invent 2023, we announced the general availability of Knowledge Bases for Amazon Bedrock. With a knowledge base, you can securely connect foundation models (FMs) in Amazon Bedrock to your company data for Retrieval Augmented Generation (RAG).
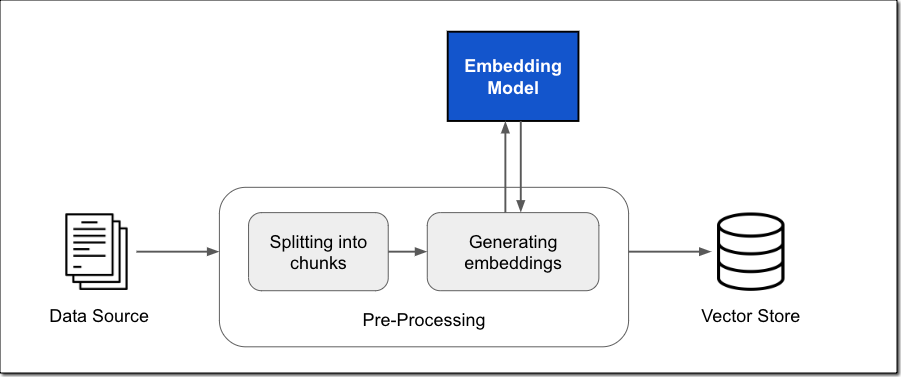
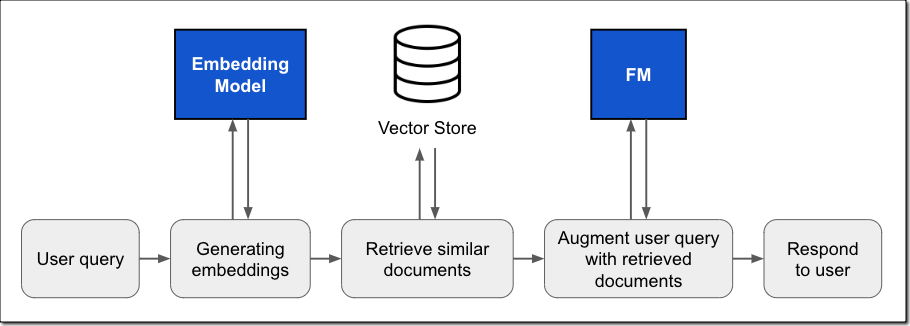
In my previous post, I described how Knowledge Bases for Amazon Bedrock manages the end-to-end RAG workflow for you. You specify the location of your data, select an embedding model to convert the data into vector embeddings, and have Amazon Bedrock create a vector store in your AWS account to store the vector data, as shown in the following figure. You can also customize the RAG workflow, for example, by specifying your own custom vector store.
Since my previous post in November, there have been a number of updates to Knowledge Bases, including the availability of Amazon Aurora PostgreSQL-Compatible Edition as an additional custom vector store option next to vector engine for Amazon OpenSearch Serverless, Pinecone, and Redis Enterprise Cloud. But that’s not all. Let me give you a quick tour of what’s new.
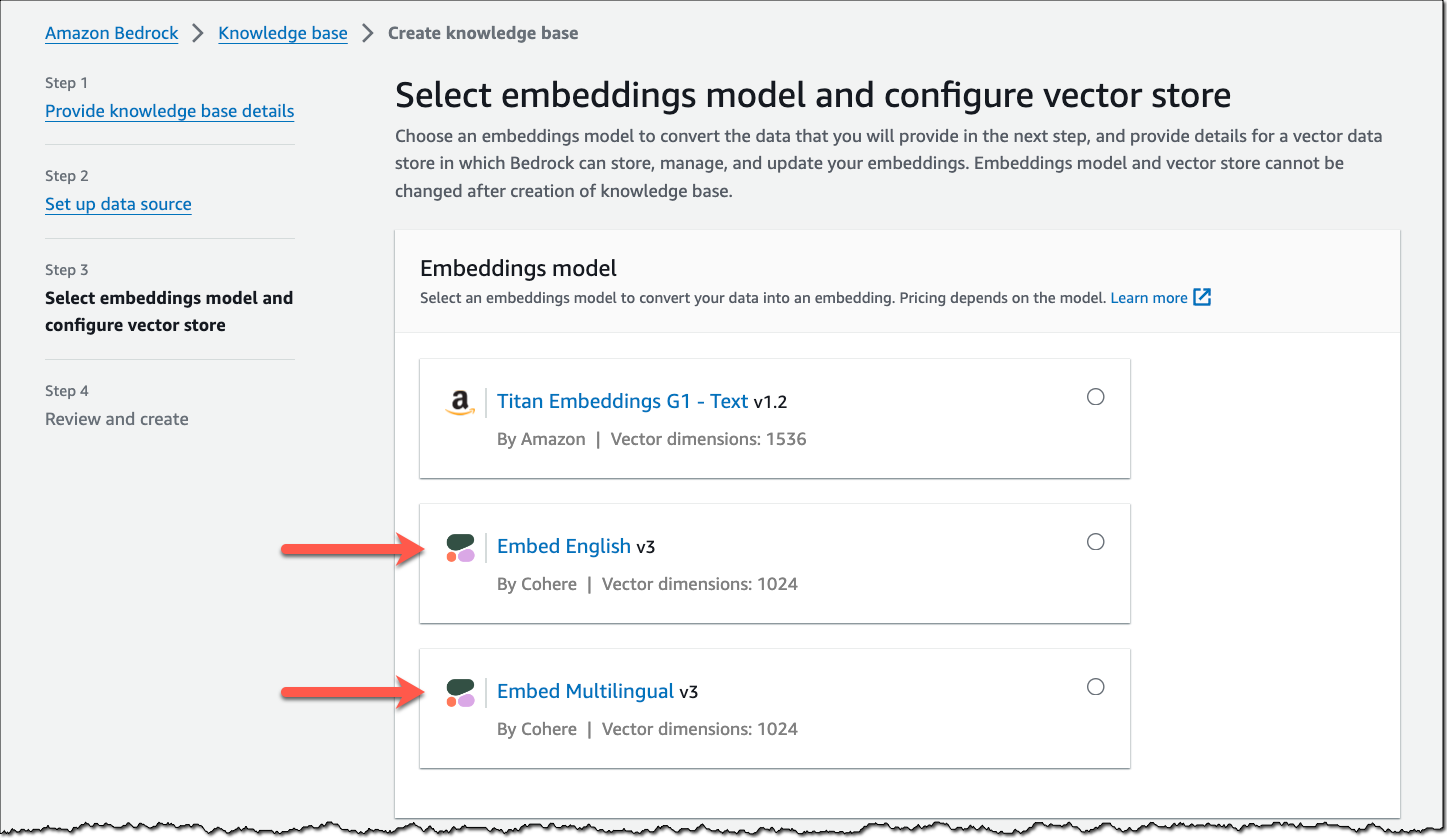
Additional choice for embedding model
The embedding model converts your data, such as documents, into vector embeddings. Vector embeddings are numeric representations of text data within your documents. Each embedding aims to capture the semantic or contextual meaning of the data.
Cohere Embed v3 – In addition to Amazon Titan Text Embeddings, you can now also choose from two additional embedding models, Cohere Embed English and Cohere Embed Multilingual, each supporting 1,024 dimensions.
Check out the Cohere Blog to learn more about Cohere Embed v3 models.
Additional choice for vector stores
Each vector embedding is put into a vector store, often with additional metadata such as a reference to the original content the embedding was created from. The vector store indexes the stored vector embeddings, which enables quick retrieval of relevant data.
Knowledge Bases gives you a fully managed RAG experience that includes creating a vector store in your account to store the vector data. You can also select a custom vector store from the list of supported options and provide the vector database index name as well as index field and metadata field mappings.
We have made three recent updates to vector stores that I want to highlight: The addition of Amazon Aurora PostgreSQL-Compatible and Pinecone serverless to the list of supported custom vector stores, as well as an update to the existing Amazon OpenSearch Serverless integration that helps to reduce cost for development and testing workloads.
Amazon Aurora PostgreSQL – In addition to vector engine for Amazon OpenSearch Serverless, Pinecone, and Redis Enterprise Cloud, you can now also choose Amazon Aurora PostgreSQL as your vector database for Knowledge Bases.
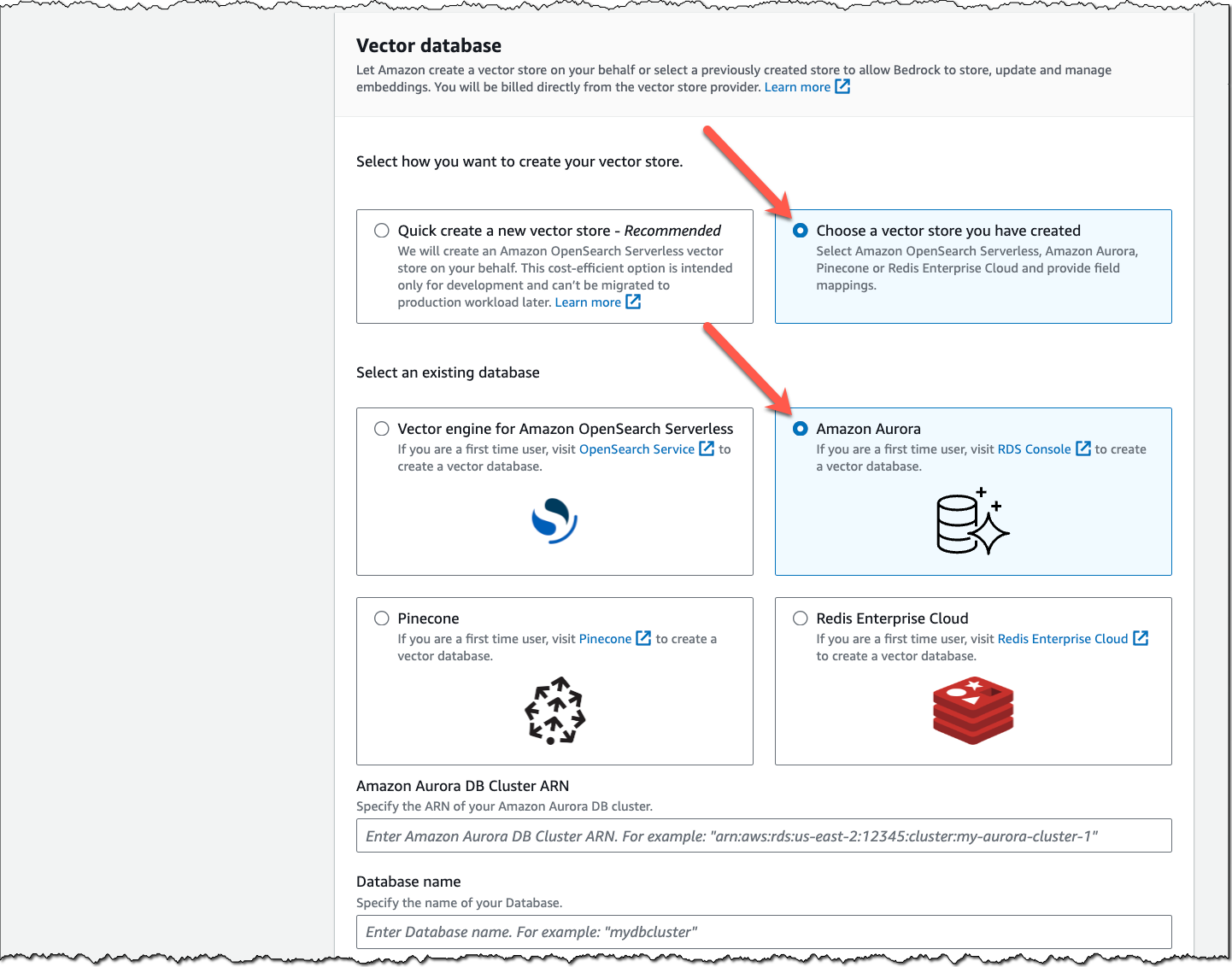
Aurora is a relational database service that is fully compatible with MySQL and PostgreSQL. This allows existing applications and tools to run without the need for modification. Aurora PostgreSQL supports the open source pgvector extension, which allows it to store, index, and query vector embeddings.
Many of Aurora’s features for general database workloads also apply to vector embedding workloads:
- Aurora offers up to 3x the database throughput when compared to open source PostgreSQL, extending to vector operations in Amazon Bedrock.
- Aurora Serverless v2 provides elastic scaling of storage and compute capacity based on real-time query load from Amazon Bedrock, ensuring optimal provisioning.
- Aurora global database provides low-latency global reads and disaster recovery across multiple AWS Regions.
- Blue/green deployments replicate the production database in a synchronized staging environment, allowing modifications without affecting the production environment.
- Aurora Optimized Reads on Amazon EC2 R6gd and R6id instances use local storage to enhance read performance and throughput for complex queries and index rebuild operations. With vector workloads that don’t fit into memory, Aurora Optimized Reads can offer up to 9x better query performance over Aurora instances of the same size.
- Aurora seamlessly integrates with AWS services such as Secrets Manager, IAM, and RDS Data API, enabling secure connections from Amazon Bedrock to the database and supporting vector operations using SQL.
For a detailed walkthrough of how to configure Aurora for Knowledge Bases, check out this post on the AWS Database Blog and the User Guide for Aurora.
Pinecone serverless – Pinecone recently introduced Pinecone serverless. If you choose Pinecone as a custom vector store in Knowledge Bases, you can provide either Pinecone or Pinecone serverless configuration details. Both options are supported.
Reduce cost for development and testing workloads in Amazon OpenSearch Serverless
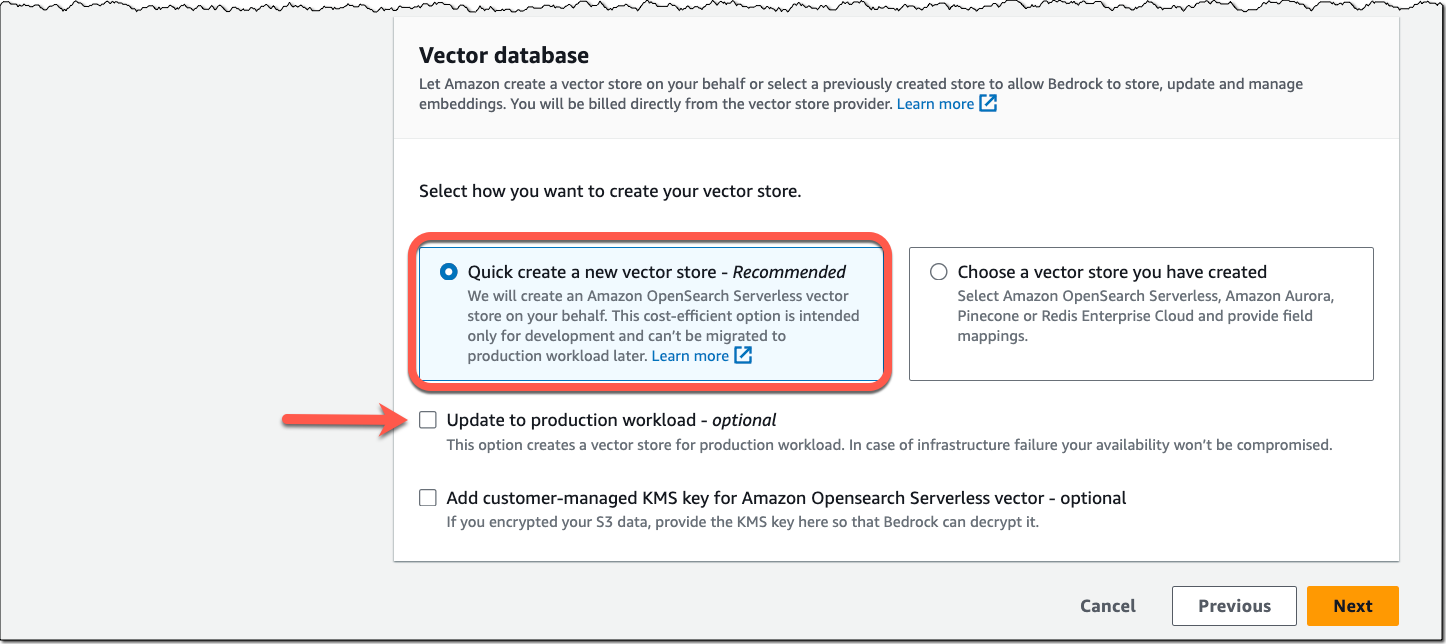
When you choose the option to quickly create a new vector store, Amazon Bedrock creates a vector index in Amazon OpenSearch Serverless in your account, removing the need to manage anything yourself.
Since becoming generally available in November, vector engine for Amazon OpenSearch Serverless gives you the choice to disable redundant replicas for development and testing workloads, reducing cost. You can start with just two OpenSearch Compute Units (OCUs), one for indexing and one for search, cutting the costs in half compared to using redundant replicas. Additionally, fractional OCU billing further lowers costs, starting with 0.5 OCUs and scaling up as needed. For development and testing workloads, a minimum of 1 OCU (split between indexing and search) is now sufficient, reducing cost by up to 75 percent compared to the 4 OCUs required for production workloads.
Usability improvement – Redundant replicas disabled is now the default selection when you choose the quick-create workflow in Knowledge Bases for Amazon Bedrock. Optionally, you can create a collection with redundant replicas by selecting Update to production workload.
For more details on vector engine for Amazon OpenSearch Serverless, check out Channy’s post.
Additional choice for FM
At runtime, the RAG workflow starts with a user query. Using the embedding model, you create a vector embedding representation of the user’s input prompt. This embedding is then used to query the database for similar vector embeddings to retrieve the most relevant text as the query result. The query result is then added to the original prompt, and the augmented prompt is passed to the FM. The model uses the additional context in the prompt to generate the completion, as shown in the following figure.
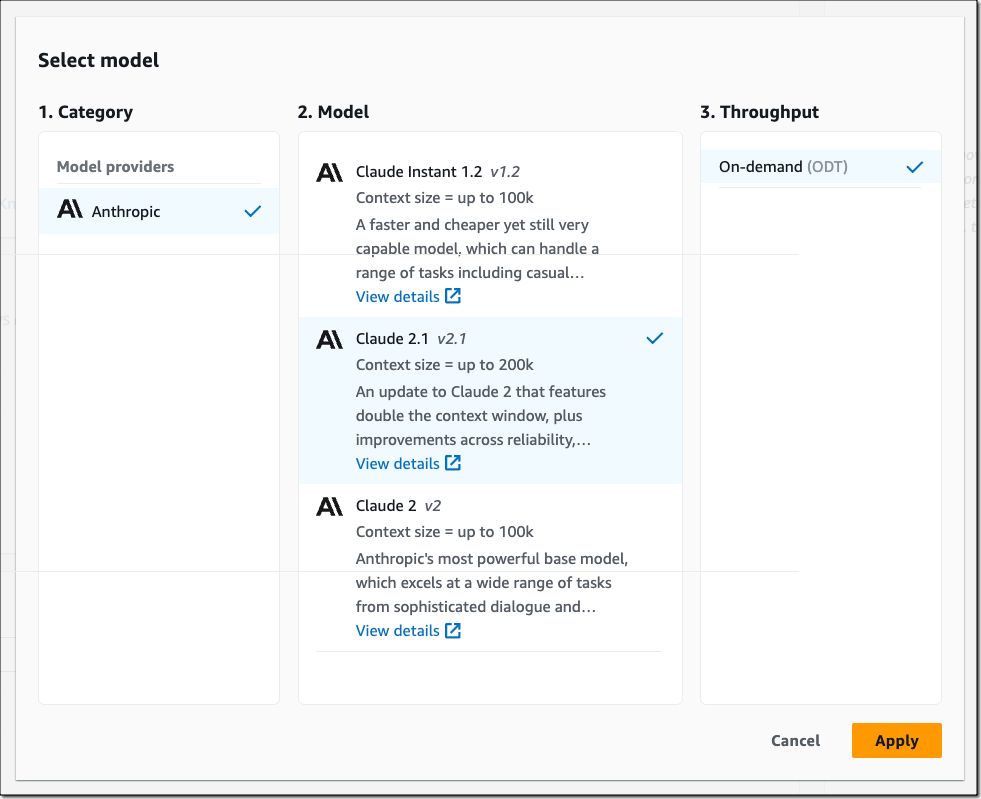
Anthropic Claude 2.1 – In addition to Anthropic Claude Instant 1.2 and Claude 2, you can now choose Claude 2.1 for Knowledge Bases. Compared to previous Claude models, Claude 2.1 doubles the supported context window size to 200 K tokens.
Check out the Anthropic Blog to learn more about Claude 2.1.
Now available
Knowledge Bases for Amazon Bedrock, including the additional choice in embedding models, vector stores, and FMs, is available in the AWS Regions US East (N. Virginia) and US West (Oregon).
Learn more
Read more about Knowledge Bases for Amazon Bedrock
— Antje