|
Today, Amazon Bedrock introduces four enhancements that streamline how you can analyze data with generative AI:
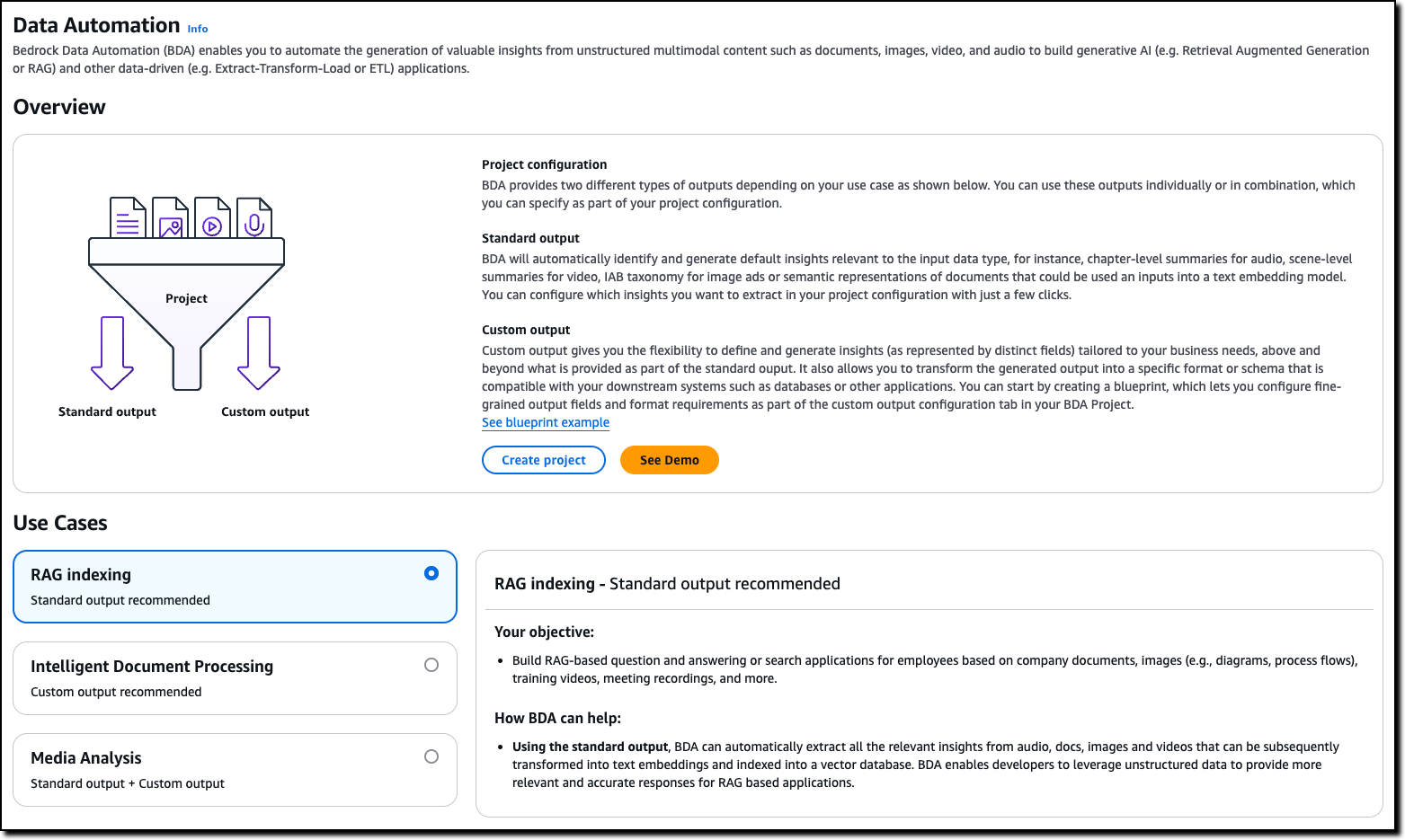
Amazon Bedrock Data Automation (preview) – A fully managed capability of Amazon Bedrock that streamlines the generation of valuable insights from unstructured, multimodal content such as documents, images, audio, and videos. With Amazon Bedrock Data Automation, you can build automated intelligent document processing (IDP), media analysis, and Retrieval-Augmented Generation (RAG) workflows quickly and cost-effectively. Insights include video summaries of key moments, detection of inappropriate image content, automated analysis of complex documents, and much more. You can customize outputs to tailor insights into your specific business needs. Amazon Bedrock Data Automation can be used as a standalone feature or as a parser when setting up a knowledge base for RAG workflows.
Amazon Bedrock Knowledge Bases now processes multimodal data –To help build applications that process both text and visual elements in documents and images, you can configure a knowledge base to parse documents using either Amazon Bedrock Data Automation or use a foundation model (FM) as the parser. Multimodal data processing can improve the accuracy and relevancy of the responses you get from a knowledge base which includes information embedded in both images and text.
Amazon Bedrock Knowledge Bases now supports GraphRAG (preview) – We now offer one of the first fully-managed GraphRAG capabilities. GraphRAG enhances generative AI applications by providing more accurate and comprehensive responses to end users by using RAG techniques combined with graphs.
Amazon Bedrock Knowledge Bases now supports structured data retrieval – This capability extends a knowledge base to support natural language querying of data warehouses and data lakes so that applications can access business intelligence (BI) through conversational interfaces and improve the accuracy of the responses by including critical enterprise data. Amazon Bedrock Knowledge Bases provides one of the first fully-managed out-of-the-box RAG solutions that can natively query structured data from where it resides. This capability helps break data silos across data sources and accelerates building generative AI applications from over a month to just a few days.
These new capabilities make it easier to build comprehensive AI applications that can process, understand, and retrieve information from structured and unstructured data sources. For example, a car insurance company can use Amazon Bedrock Data Automation to automate their claims adjudication workflow to reduce the time taken to process automobile claims, improving the productivity of their claims department.
Similarly, a media company can analyze TV shows and extract insights needed for smart advertisement placement such as scene summaries, industry standard advertising taxonomies (IAB), and company logos. A media production company can generate scene-by-scene summaries and capture key moments in their video assets. A financial services company can process complex financial documents containing charts and tables and use GraphRAG to understand relationships between different financial entities. All these companies can use structured data retrieval to query their data warehouse while retrieving information from their knowledge base.
Let’s take a closer look at these features.
Introducing Amazon Bedrock Data Automation
Amazon Bedrock Data Automation is a capability of Amazon Bedrock that simplifies the process of extracting valuable insights from multimodal, unstructured content, such as documents, images, videos, and audio files.
Amazon Bedrock Data Automation provides a unified, API-driven experience that developers can use to process multimodal content through a single interface, eliminating the need to manage and orchestrate multiple AI models and services. With built-in safeguards, such as visual grounding and confidence scores, Amazon Bedrock Data Automation helps promote the accuracy and trustworthiness of the extracted insights, making it easier to integrate into enterprise workflows.
Amazon Bedrock Data Automation supports 4 modalities (documents, images, video, and audio). When used in an application, all modalities use the same asynchronous inference API, and results are written to an Amazon Simple Storage Service (Amazon S3) bucket.
For each modality, you can configure the output based on your processing needs and generate two types of outputs:
Standard output – With standard output, you get predefined default insights that are relevant to the input data type. Examples include semantic representation of documents, summaries of videos by scene, audio transcripts and more. You can configure which insights you want to extract with just a few steps.
Custom output – With custom output, you have the flexibility to define and specify your extraction needs using artifacts called “blueprints” to generate insights tailored to your business needs. You can also transform the generated output into a specific format or schema that is compatible with your downstream systems such as databases or other applications.
Standard output can be used with all formats (audio, documents, images, and videos). During the preview, custom output can only be used with documents and images.
Both standard and custom output configurations can be saved in a project to reference in the Amazon Bedrock Data Automation inference API. A project can be configured to generate both standard output and custom output for each processed file.
Let’s look at an example of processing a document for both standard and custom outputs.
Using Amazon Bedrock Data Automation
On the Amazon Bedrock console, I choose Data Automation in the navigation pane. Here, I can review how this capability works with a few sample use cases.
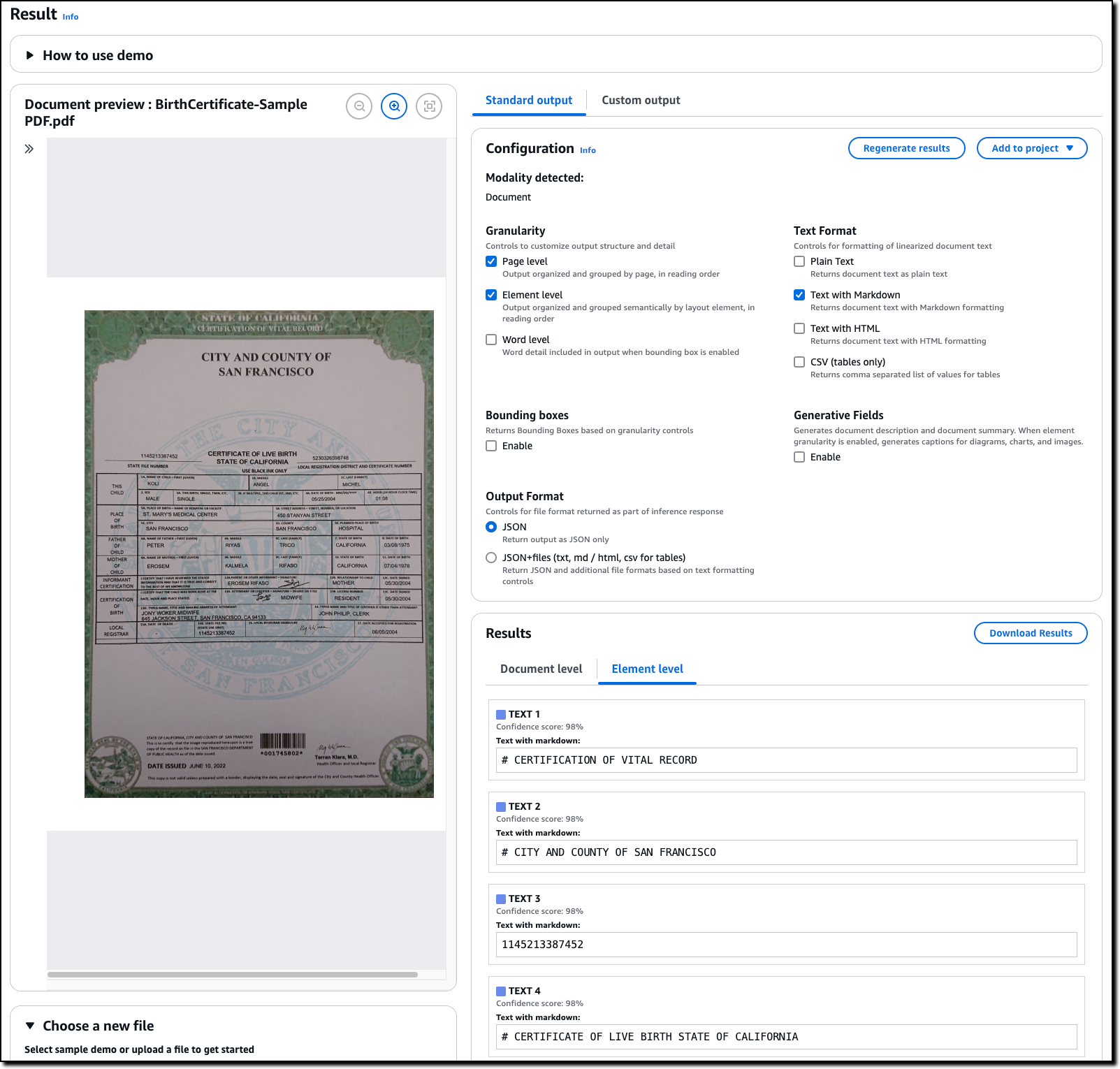
Then, I choose Demo in the Data Automation section of the navigation pane. I can try this capability using one of the provided sample documents or by uploading my own. For example, let’s say I am working on an application that needs to process birth certificates.
I start by uploading a birth certificate to see the standard output results. The first time I upload a document, I’m asked to confirm to create an S3 bucket to store the assets. When I look at the standard output, I can tailor the result with a few quick settings.
I choose the Custom output tab. The document is recognized by one of the sample blueprints and information is extracted across multiple fields.
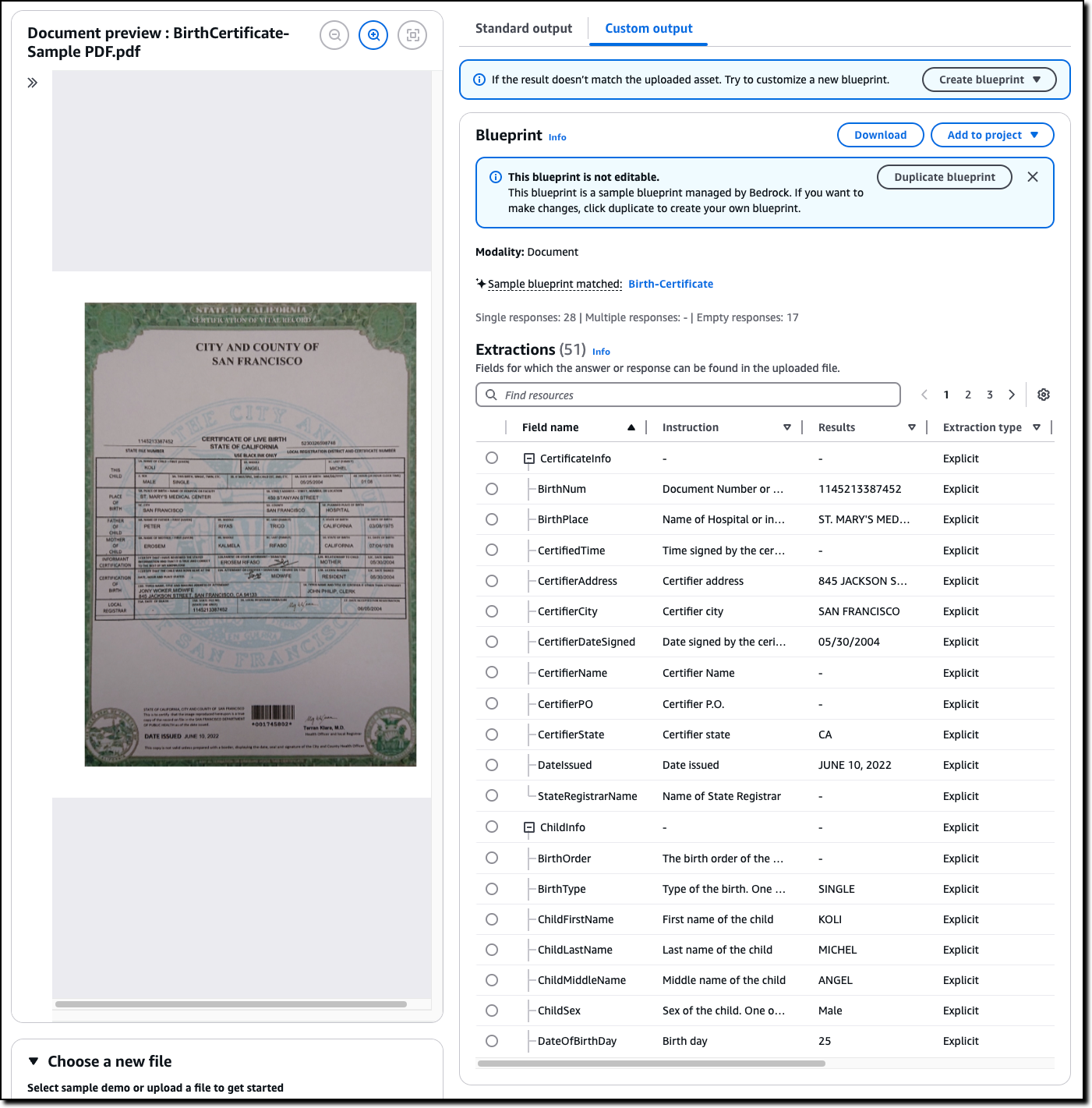
Most of the data for my application is there but I need a few customizations. For example, the date the birth certificate was issued (JUNE 10, 2022) is in a different format than the other dates in the document. I also need the state that issued the certificate and a couple of flags that tell me if the child last name matches the one from the mother or the father.
Most of the fields in the previous blueprint use the Explicit extraction type. That means they’re extracted as they are from the document.
If I want a date in a specific format, I can create a new field using the Inferred extraction type and add instructions on how to format the result starting from the content of the document. Inferred extractions can be used to perform transformations, such as date or Social Security number (SSN) format, or validations, for example, to check if a person is over 21 based on today’s date.
Sample blueprints cannot be edited. I choose Duplicate blueprint to create a new blueprint that I can edit and then Add field from the Fields drop down.
I add four fields with extraction type Inferred and these instructions:
The date the birth certificate was issued in MM/DD/YYYY formatThe state that issued the birth certificateIs ChildLastName equal to FatherLastNameIs ChildLastName equal to MotherLastName
The first two fields are strings and the last two booleans.
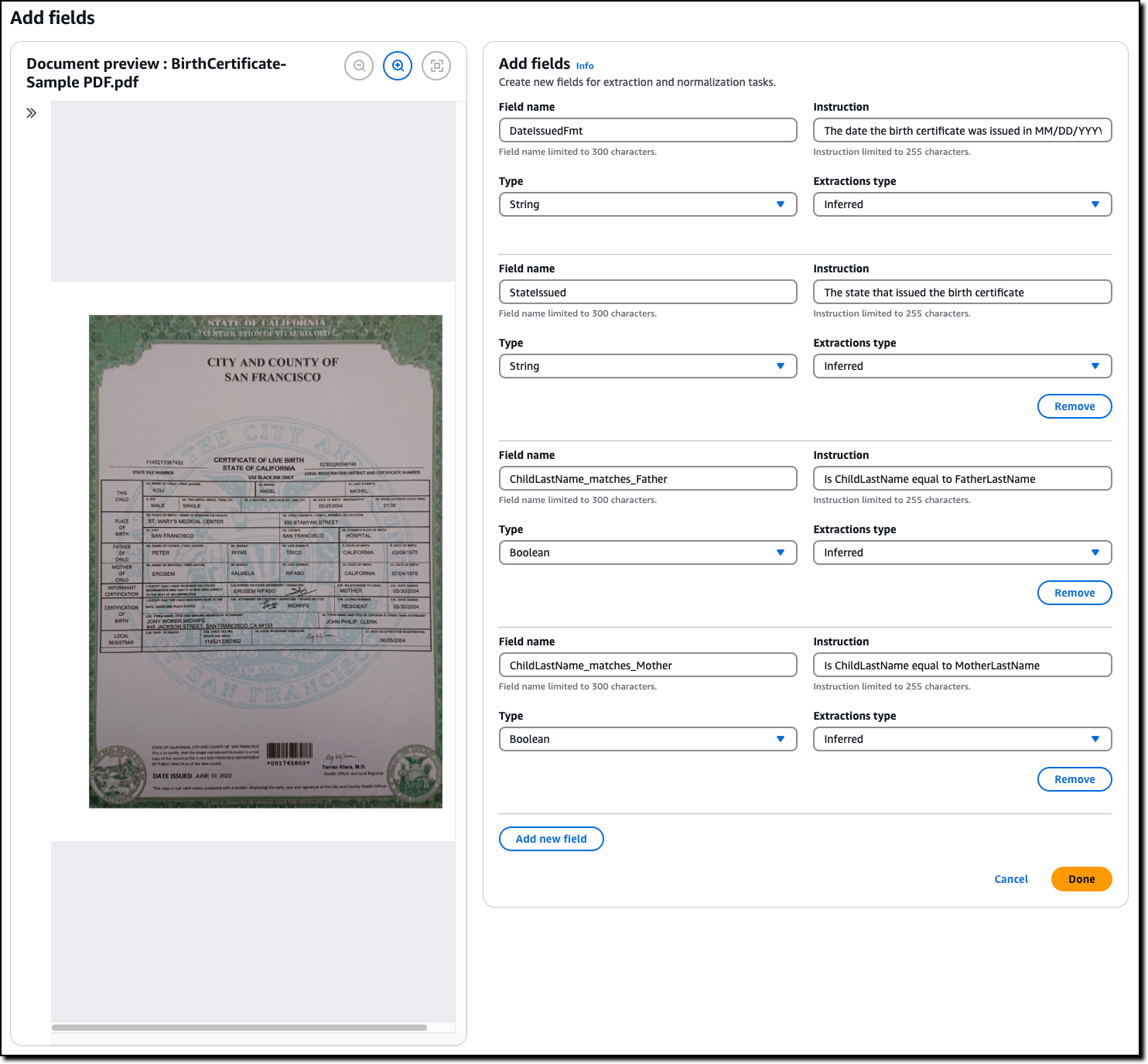
After I create the new fields, I can apply the new blueprint to the document I previously uploaded.
I choose Get result and look for the new fields in the results. I see the date formatted as I need, the two flags, and the state.
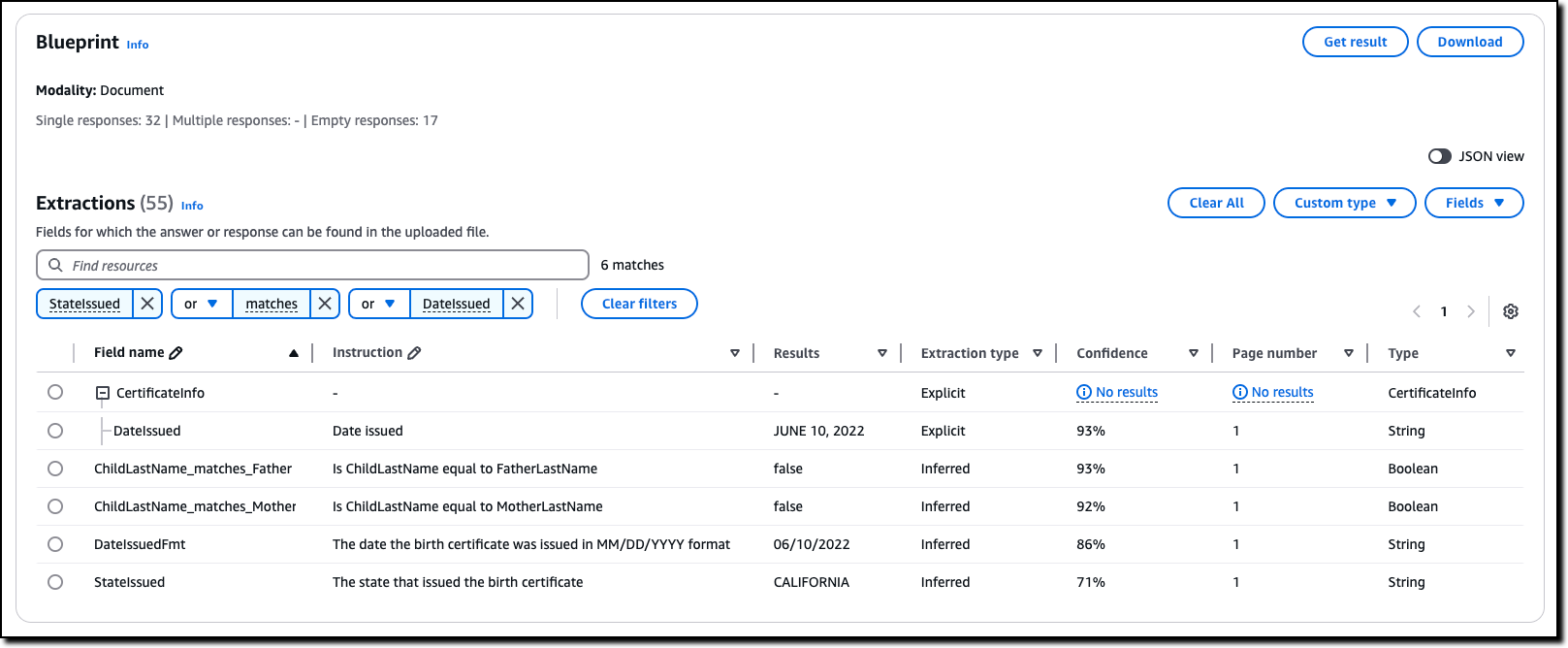
Now that I have created this custom blueprint tailored to the needs of my application, I can add it to a project. I can associate multiple blueprints with a project for the different document types I want to process, such as a blueprint for passports, a blueprint for birth certificates, a blueprint for invoices, and so on. When processing documents, Amazon Bedrock Data Automation matches each document to a blueprints within the project to extract relevant information.
I can also create a new blueprint form scratch. In that case, I can start with a prompt where I declare any fields I expect to find in the uploaded document and perform normalizations or validations.
Amazon Bedrock Data Automation can also process audio and video files. For example, here’s the standard output when uploading a video from a keynote presentation by Swami Sivasubramanian VP, AI and Data at AWS.
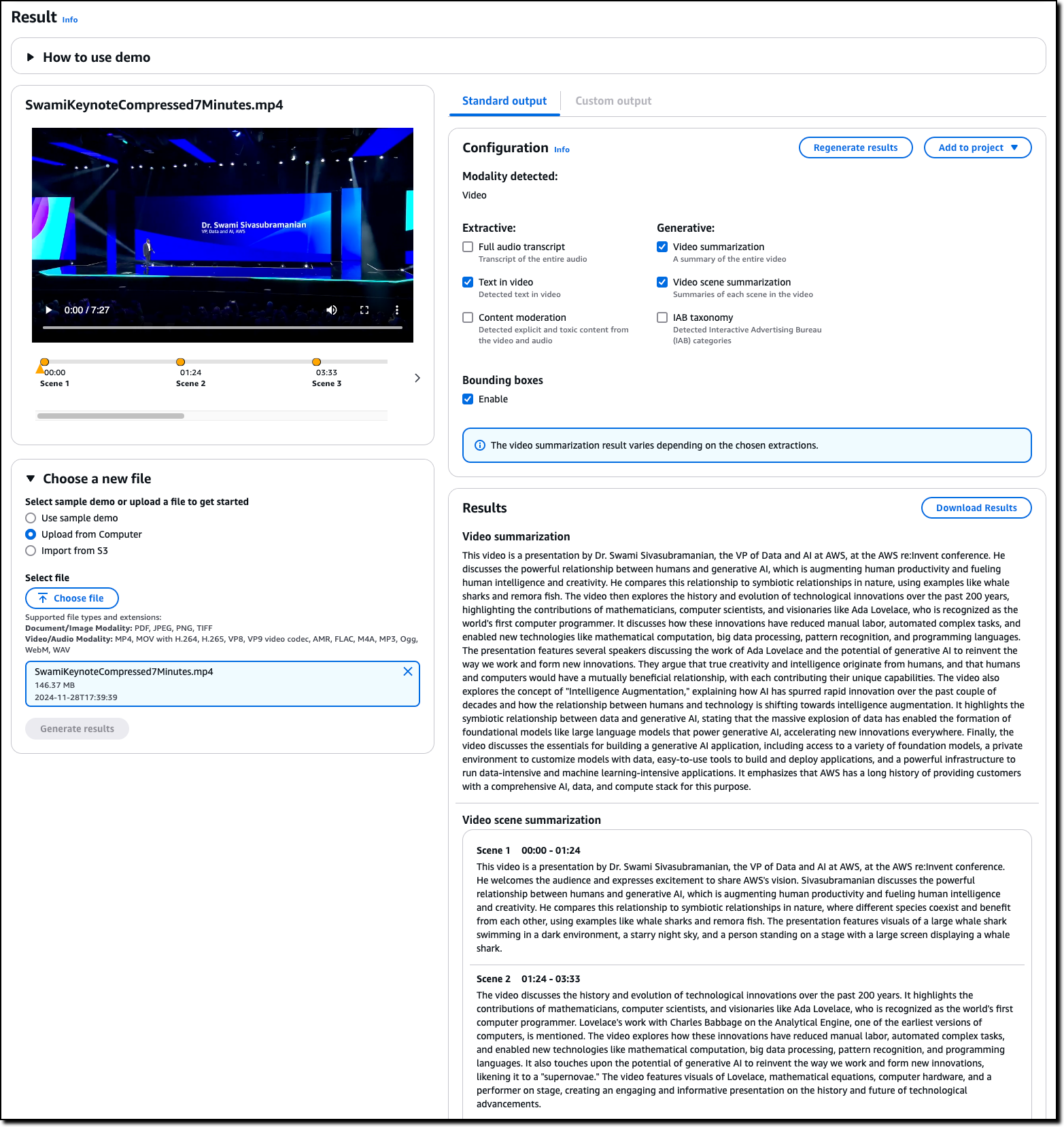
It takes a few minutes to get the output. The results include a summarization of the overall video, a summary scene by scene, and the text that appears during the video. From here, I can toggle the options to have a full audio transcript, content moderation, or Interactive Advertising Bureau (IAB) taxonomy.
I can also use Amazon Bedrock Data Automation as a parser when creating a knowledge base to extract insights from visually rich documents and images, for retrieval and response generation. Let’s see that in the next section.
Using multimodal data processing in Amazon Bedrock Knowledge Bases
Multimodal data processing support enables applications to understand both text and visual elements in documents.
With multimodal data processing, applications can use a knowledge base to:
- Retrieve answers from visual elements in addition to existing support of text.
- Generate responses based on the context that includes both text and visual data.
- Provide source attribution that references visual elements from the original documents.
When creating a knowledge base in the Amazon Bedrock console, I now have the option to select Amazon Bedrock Data Automation as Parsing strategy.
When I select Amazon Bedrock Data Automation as parser, Amazon Bedrock Data Automation handles the extraction, transformation, and generation of insights from visually rich content, while Amazon Bedrock Knowledge Bases manages ingestion, retrieval, model response generation, and source attribution.
Alternatively, I can use the existing Foundation models as a parser option. With this option, there’s now support for Anthropic’s Claude 3.5 Sonnet as parser, and I can use the default prompt or modify it to suit a specific use case.
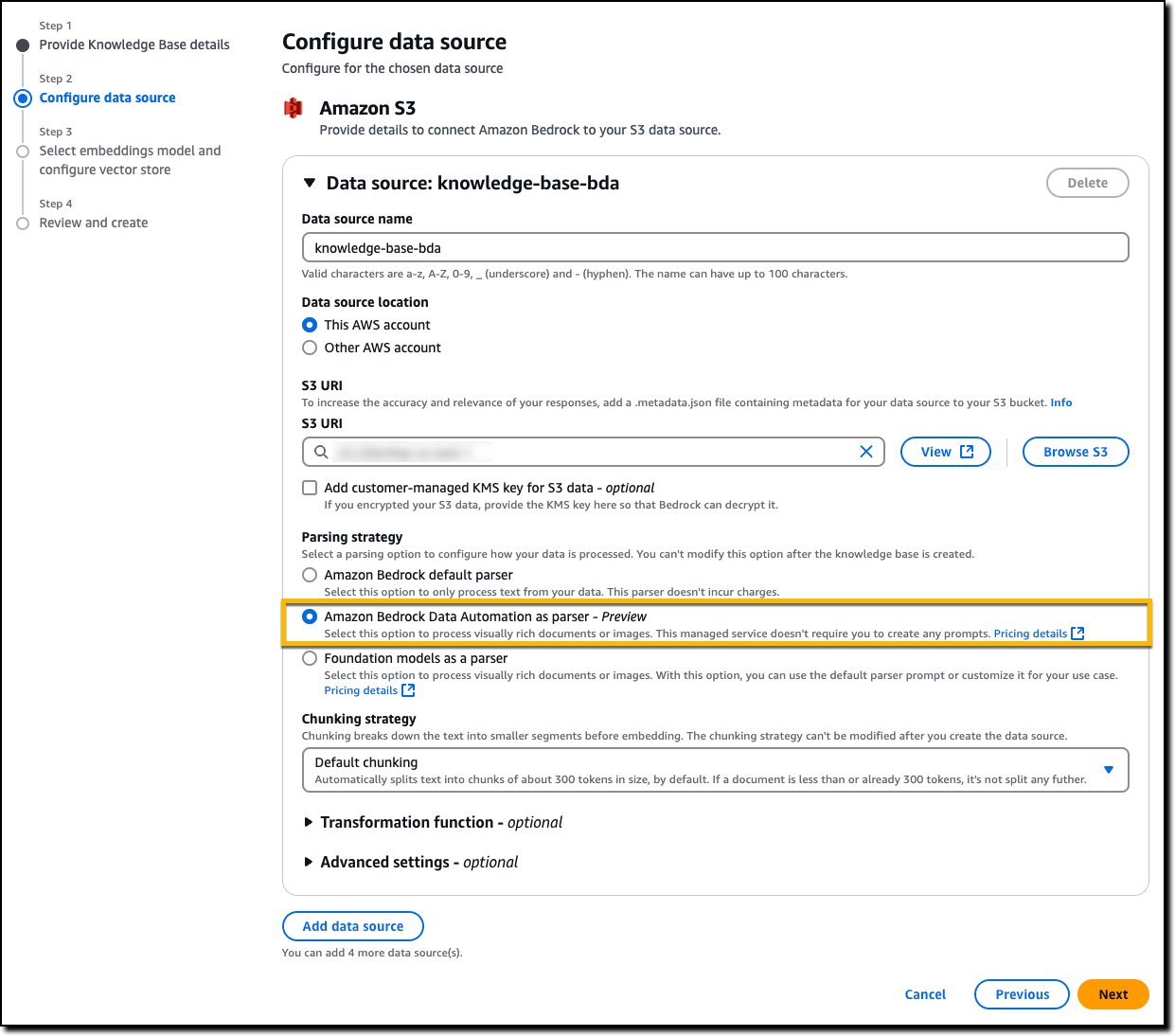
In the next step, I specify the Multimodal storage destination on Amazon S3 that will be used by Amazon Bedrock Knowledge Bases to store images extracted from my documents in the knowledge base data source. These images can be retrieved based on a user query, used to generate the response, and cited in the response.
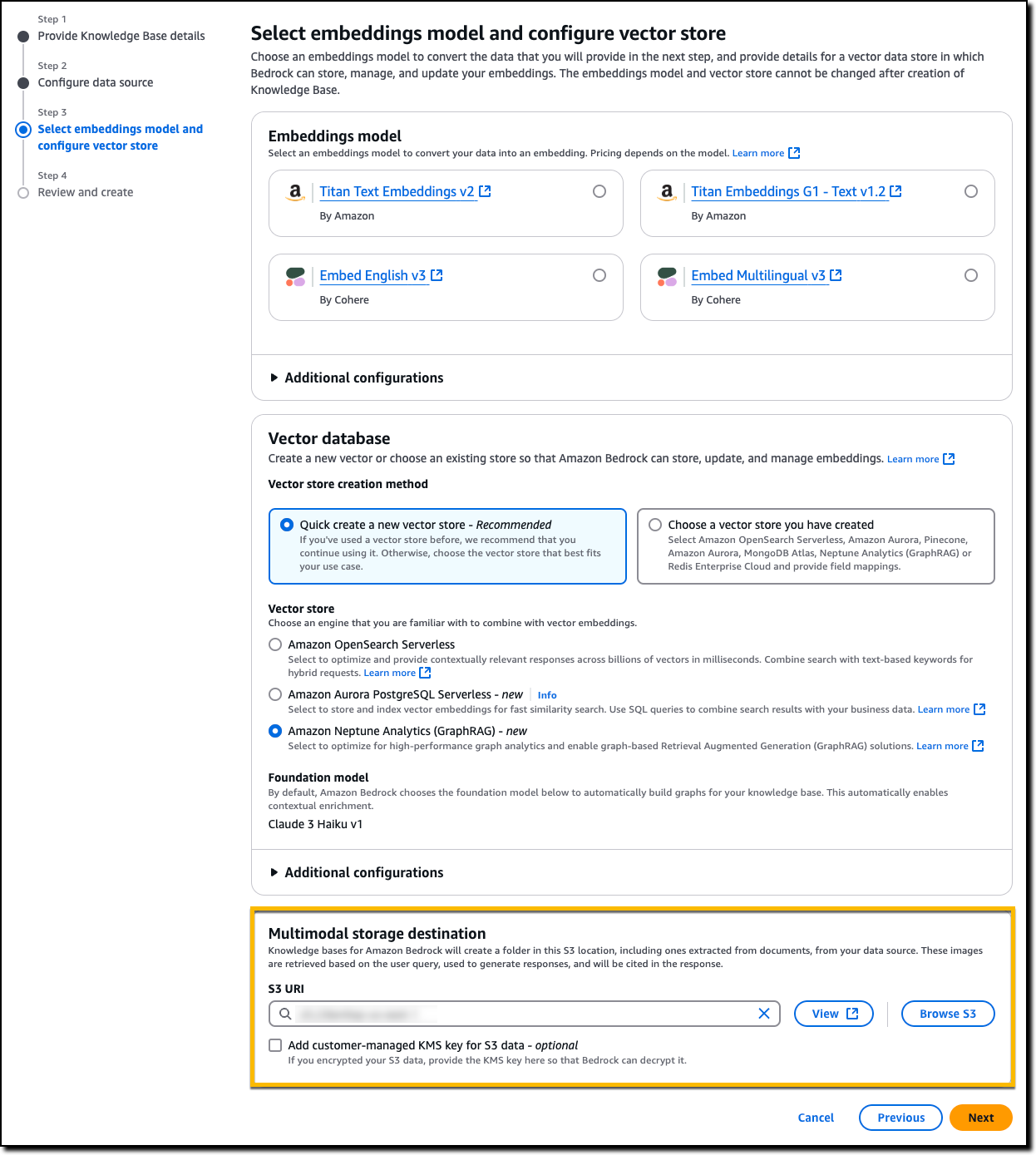
When using the knowledge base, the information extracted by Amazon Bedrock Data Automation or FMs as parser is used to retrieve information about visual elements, understand charts and diagrams, and provide responses that reference both textual and visual content.
Using GraphRAG in Amazon Bedrock Knowledge Bases
Extracting insights from scattered data sources presents significant challenges for RAG applications, requiring multi-step reasoning across these data sources to generate relevant responses. For example, a customer might ask a generative AI-powered travel application to identify family-friendly beach destinations with direct flights from their home location that also offer good seafood restaurants. This requires a connected workflow to identify suitable beaches that other families have enjoyed, match these to flight routes, and select highly-rated local restaurants. A traditional RAG system may struggle to synthesize all these pieces into a cohesive recommendation because the information lives in disparate sources and is not interlinked.
Knowledge graphs can address this challenge by modeling complex relationships between entities in a structured way. However, building and integrating graphs into an application requires significant expertise and effort.
Amazon Bedrock Knowledge Bases now offers one of the first fully managed GraphRAG capabilities that enhances generative AI applications by providing more accurate and comprehensive responses to end users by using RAG techniques combined with graphs.
When creating a knowledge base, I can now enable GraphRAG in just a few steps by choosing Amazon Neptune Analytics as database, automatically generating vector and graph representations of the underlying data, entities and their relationships, and reducing development effort from several weeks to just a few hours.
I start the creation of new knowledge base. In the Vector database section, when creating a new vector store, I select Amazon Neptune Analytics (GraphRAG). If I don’t want to create a new graph, I can provide an existing vector store and select a Neptune Analytics graph from the list. GraphRAG uses Anthropic’s Claude 3 Haiku to automatically build graphs for a knowledge base.
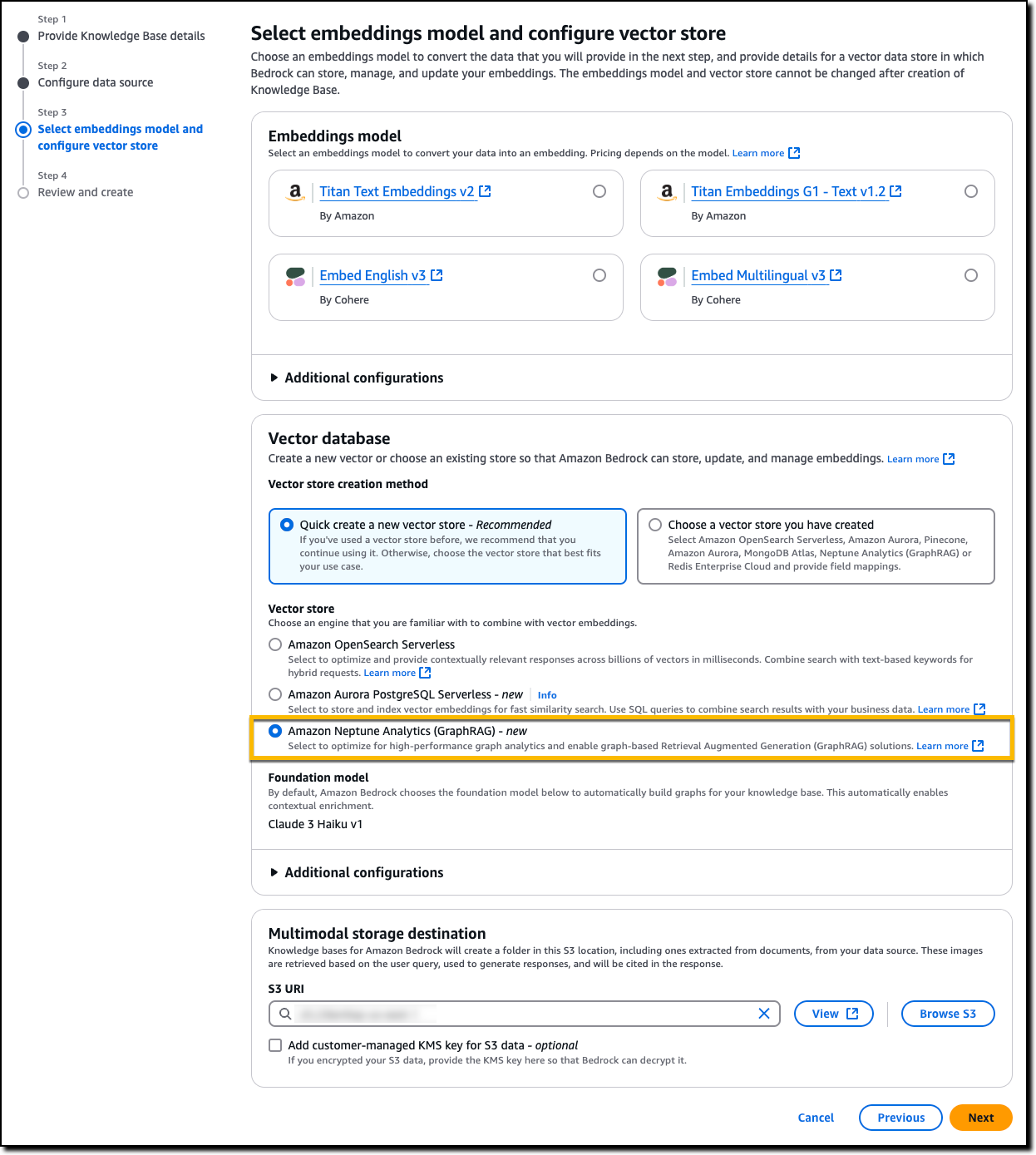
After I complete the creation of the knowledge base, Amazon Bedrock automatically builds a graph, linking related concepts and documents. When retrieving information from the knowledge base, GraphRAG traverses these relationships to provide more comprehensive and accurate responses.
Using structured data retrieval in Amazon Bedrock Knowledge Bases
Structured data retrieval allows natural language querying of databases and data warehouses. For example, a business analyst might ask, “What were our top-selling products last quarter?” and the system automatically generates and runs the appropriate SQL query for a data warehouse stored in an Amazon Redshift database.
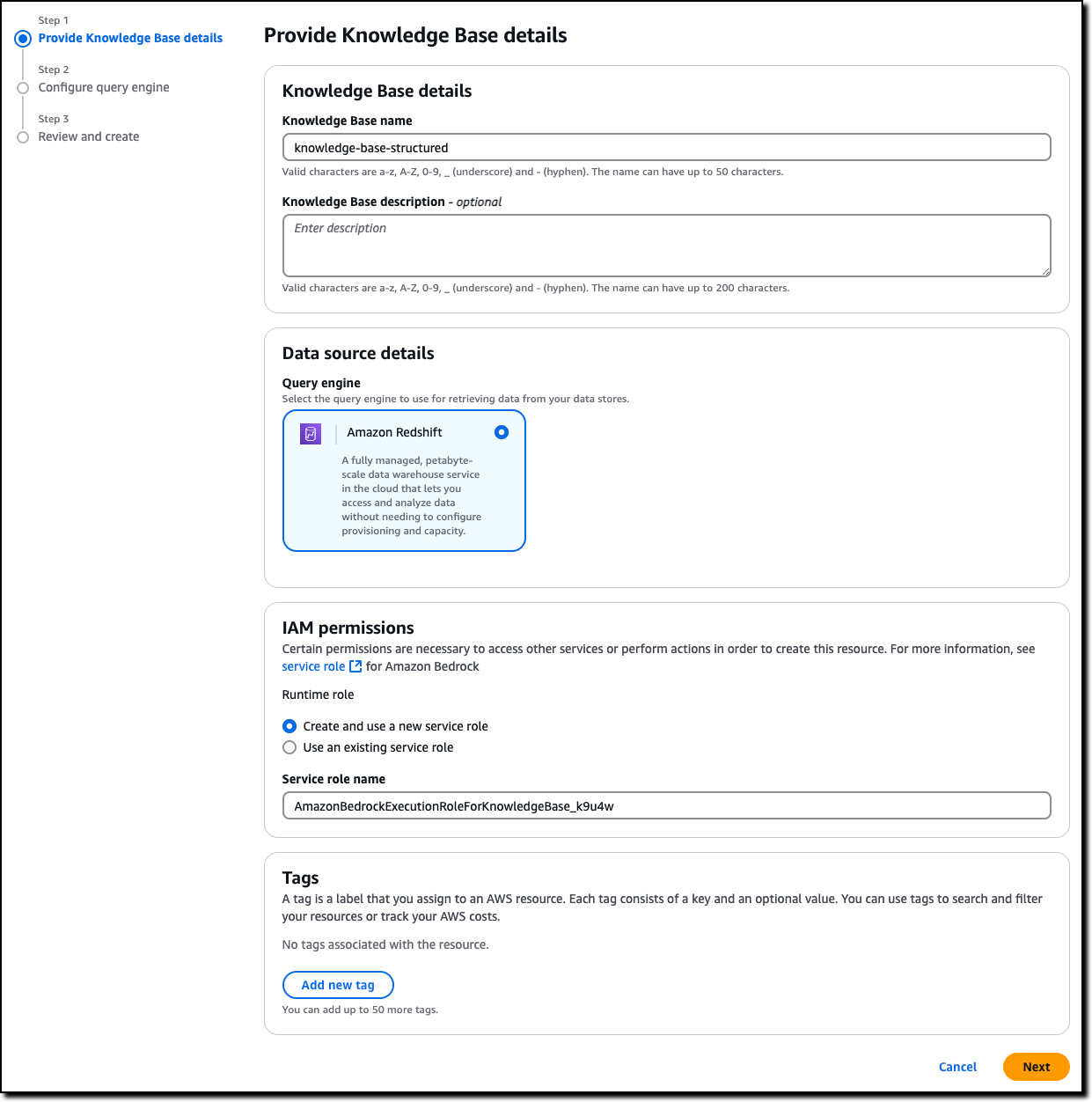
When creating a knowledge base, I now have the option to use a structured data store.

I enter a name and description for the knowledge base. In Data source details, I use Amazon Redshift as Query engine. I create a new AWS Identity and Access Management (IAM) service role to manage the knowledge base resources and choose Next.
I choose Redshift serverless in Connection options and the Workgroup to use. Amazon Redshift provisioned clusters are also supported. I use the previously created IAM role for Authentication. Storage metadata can be managed with AWS Glue Data Catalog or directly within an Amazon Redshift database. I select a database from the list.
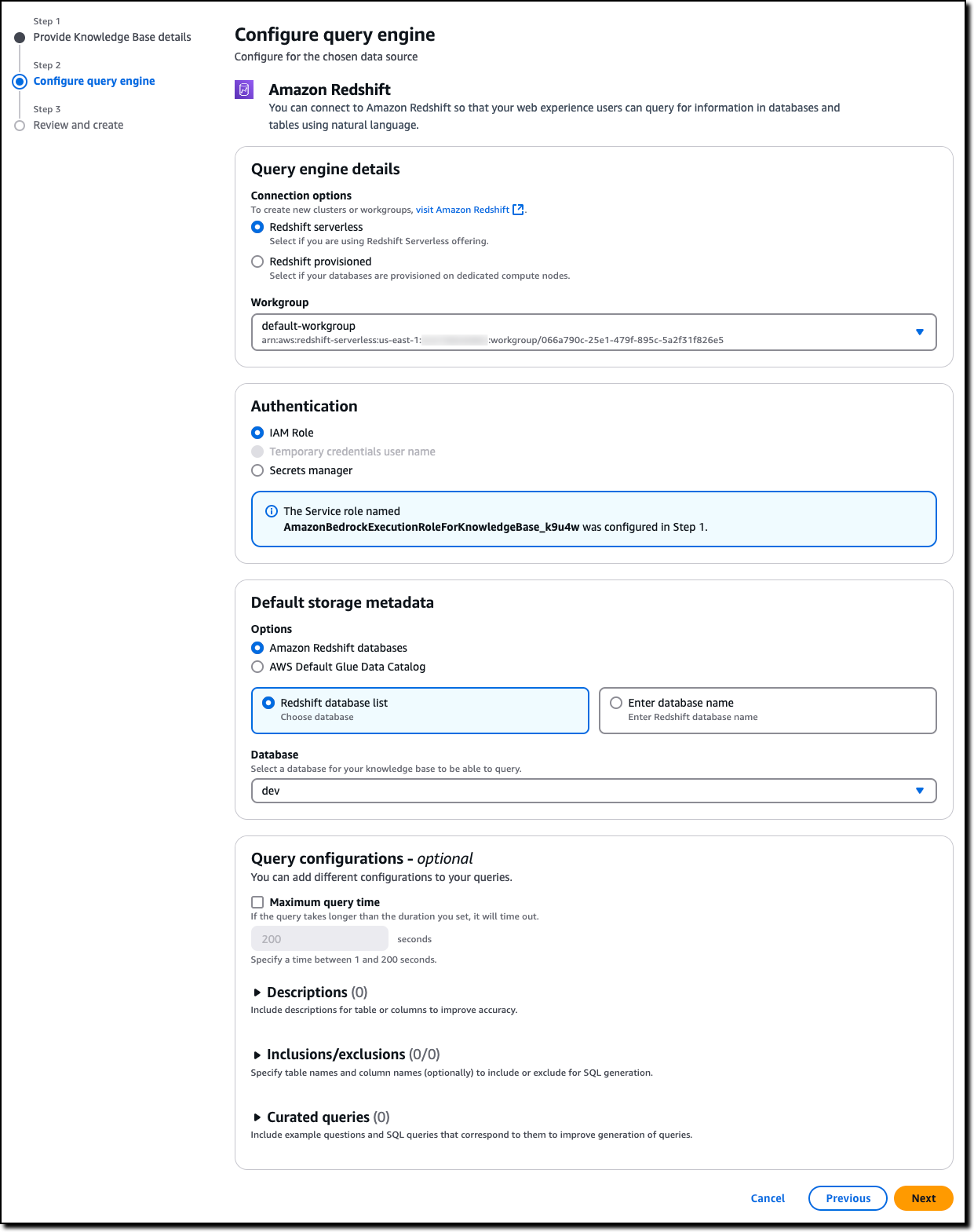
In the configuration of the knowledge base, I can define the maximum duration for a query and include or exclude access to tables or columns. To improve the accuracy of query generation from natural language, I can optionally add a description for tables and columns and a list of curated queries that provides practical examples of how to translate a question into a SQL query for my database. I choose Next, review the settings, and complete the creation of the knowledge base
After a few minutes, the knowledge base is ready. Once synced, Amazon Bedrock Knowledge Bases handles generating, running, and formatting the result of the query, making it easy to build natural language interfaces to structured data. When invoking a knowledge base using structured data, I can ask to only generate SQL, retrieve data, or summarize the data in natural language.
Things to know
These new capabilities are available today in the following AWS Regions:
- Amazon Bedrock Data Automation is available in preview in US West (Oregon).
- Multimodal data processing support in Amazon Bedrock Knowledge Bases using Amazon Bedrock Data Automation as parser is available in preview in US West (Oregon). FM as a parser is available in all Regions where Amazon Bedrock Knowledge Bases is offered.
- GraphRAG in Amazon Bedrock Knowledge Bases is available in preview in all commercial Regions where Amazon Bedrock Knowledge Bases and Amazon Neptune Analytics are offered.
- Structured data retrieval is available in Amazon Bedrock Knowledge Bases in all commercial Regions where Amazon Bedrock Knowledge Bases is offered.
As usual with Amazon Bedrock, pricing is based on usage:
- Amazon Bedrock Data Automation charges per images, per page for documents, and per minute for audio or video.
- Multimodal data processing in Amazon Bedrock Knowledge Bases is charged based on the use of either Amazon Bedrock Data Automation or the FM as parser.
- There is no additional cost for using GraphRAG in Amazon Bedrock Knowledge Bases but you pay for using Amazon Neptune Analytics as the vector store. For more information, visit Amazon Neptune pricing.
- There is an additional cost when using structured data retrieval in Amazon Bedrock Knowledge Bases.
For detailed pricing information, see Amazon Bedrock pricing.
Each capability can be used independently or in combination. Together, they make it easier and faster to build applications that use AI to process data. To get started, visit the Amazon Bedrock console. To learn more, you can access the Amazon Bedrock documentation and send feedback to AWS re:Post for Amazon Bedrock. You can find deep-dive technical content and discover how our Builder communities are using Amazon Bedrock at community.aws. Let us know what you build with these new capabilities!
— Danilo