|
Today, we’re announcing the general availability of Amazon Elastic Compute Cloud (Amazon EC2) P5en instances, powered by NVIDIA H200 Tensor Core GPUs and custom 4th generation Intel Xeon Scalable processors with an all-core turbo frequency of 3.2 GHz (max core turbo frequency of 3.8 GHz) available only on AWS. These processors offer 50 percent higher memory bandwidth and up to four times throughput between CPU and GPU with PCIe Gen5, which help boost performance for machine learning (ML) training and inference workloads.
P5en, with up to 3200 Gbps of third generation of Elastic Fabric Adapter (EFAv3) using Nitro v5, shows up to 35% improvement in latency compared to P5 that uses the previous generation of EFA and Nitro. This helps improve collective communications performance for distributed training workloads such as deep learning, generative AI, real-time data processing, and high-performance computing (HPC) applications.
Here are the specs for P5en instances:
| Instance size | vCPUs | Memory (GiB) | GPUs (H200) | Network bandwidth (Gbps) | GPU Peer to peer (GB/s) | Instance storage (TB) | EBS bandwidth (Gbps) |
| p5en.48xlarge | 192 | 2048 | 8 | 3200 | 900 | 8 x 3.84 | 100 |
On September 9, we introduced Amazon EC2 P5e instances, powered by 8 NVIDIA H200 GPUs with 1128 GB of high bandwidth GPU memory, 3rd Gen AMD EPYC processors, 2 TiB of system memory, and 30 TB of local NVMe storage. These instances provide up to 3,200 Gbps of aggregate network bandwidth with EFAv2 and support GPUDirect RDMA, enabling lower latency and efficient scale-out performance by bypassing the CPU for internode communication.
With P5en instances, you can increase the overall efficiency in a wide range of GPU-accelerated applications by further reducing the inference and network latency. P5en instances increases local storage performance by up to two times and Amazon Elastic Block Store (Amazon EBS) bandwidth by up to 25 percent compared with P5 instances, which will further improve inference latency performance for those of you who are using local storage for caching model weights.
The transfer of data between CPUs and GPUs can be time-consuming, especially for large datasets or workloads that require frequent data exchanges. With PCIe Gen 5 providing up to four times bandwidth between CPU and GPU compared with P5eand P5e instances, you can further improve latency for model training, fine-tuning, and running inference for complex large language models (LLMs) and multimodal foundation models (FMs), and memory-intensive HPC applications such as simulations, pharmaceutical discovery, weather forecasting, and financial modeling.
Getting started with Amazon EC2 P5en instances
You can use EC2 P5en instances available in the US East (Ohio), US West (Oregon), and Asia Pacific (Tokyo) AWS Regions through EC2 Capacity Blocks for ML, On Demand, and Savings Plan purchase options.
I want to introduce how to use P5en instances with Capacity Reservation as an option. To reserve your EC2 Capacity Blocks, choose Capacity Reservations on the Amazon EC2 console in the US East (Ohio) AWS Region.
Select Purchase Capacity Blocks for ML and then choose your total capacity and specify how long you need the EC2 Capacity Block for p5en.48xlarge instances. The total number of days that you can reserve EC2 Capacity Blocks is 1–14, 21, or 28 days. EC2 Capacity Blocks can be purchased up to 8 weeks in advance.
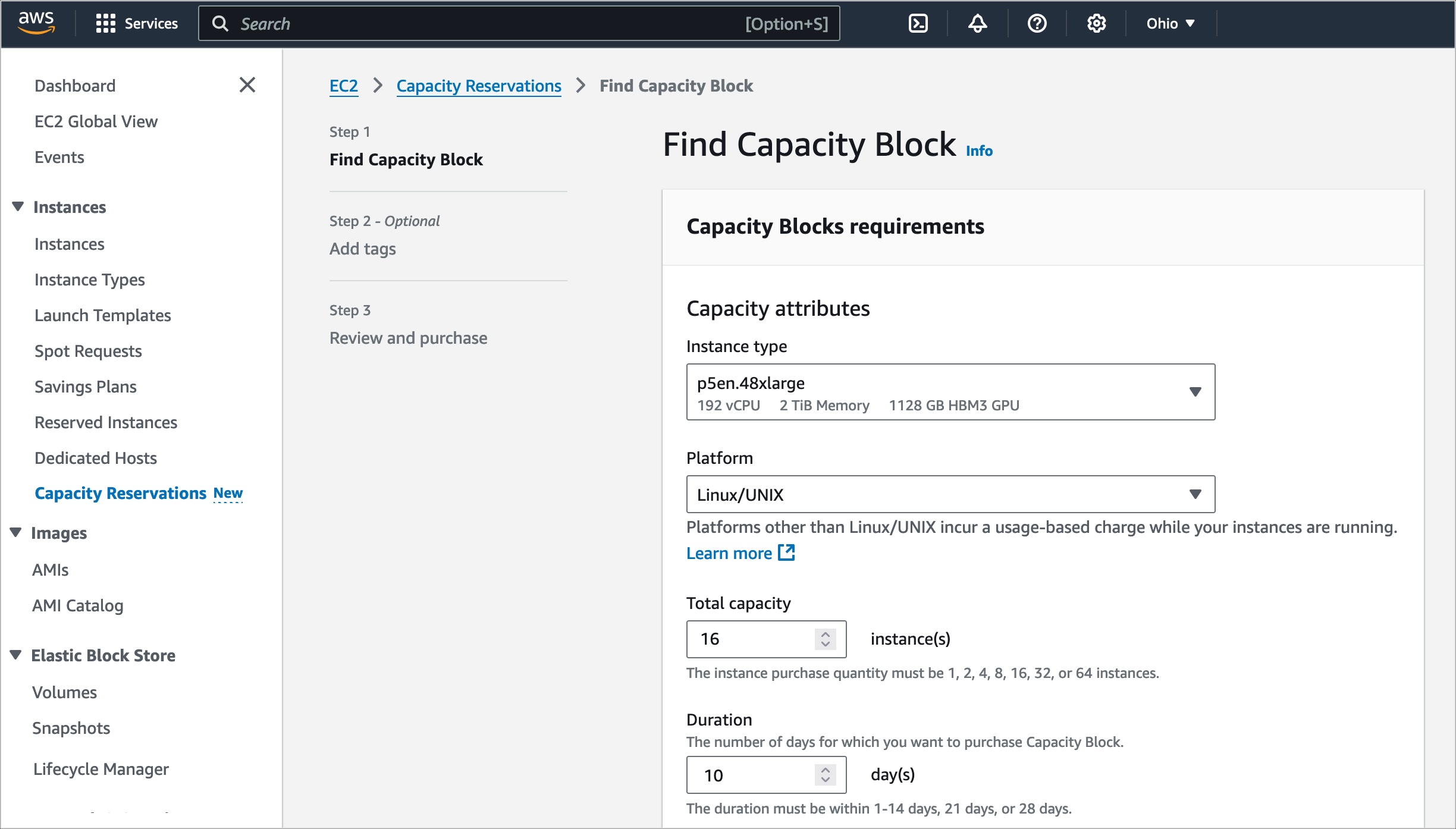
When you select Find Capacity Blocks, AWS returns the lowest-priced offering available that meets your specifications in the date range you have specified. After reviewing EC2 Capacity Blocks details, tags, and total price information, choose Purchase.
Now, your EC2 Capacity Block will be scheduled successfully. The total price of an EC2 Capacity Block is charged up front, and the price does not change after purchase. The payment will be billed to your account within 12 hours after you purchase the EC2 Capacity Blocks. To learn more, visit Capacity Blocks for ML in the Amazon EC2 User Guide.
To run instances within your purchased Capacity Block, you can use AWS Management Console, AWS Command Line Interface (AWS CLI) or AWS SDKs.
Here is a sample AWS CLI command to run 16 P5en instances to maximize EFAv3 benefits. This configuration provides up to 3200 Gbps of EFA networking bandwidth and up to 800 Gbps of IP networking bandwidth with eight private IP address:
$ aws ec2 run-instances --image-id ami-abc12345
--instance-type p5en.48xlarge
--count 16
--key-name MyKeyPair
--instance-market-options MarketType='capacity-block'
--capacity-reservation-specification CapacityReservationTarget={CapacityReservationId=cr-a1234567}
--network-interfaces "NetworkCardIndex=0,DeviceIndex=0,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa"
"NetworkCardIndex=1,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only"
"NetworkCardIndex=2,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only"
"NetworkCardIndex=3,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only"
"NetworkCardIndex=4,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa"
"NetworkCardIndex=5,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only"
"NetworkCardIndex=6,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only"
"NetworkCardIndex=7,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only"
"NetworkCardIndex=8,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa"
"NetworkCardIndex=9,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only"
"NetworkCardIndex=10,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only"
"NetworkCardIndex=11,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only"
"NetworkCardIndex=12,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa"
"NetworkCardIndex=13,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only"
"NetworkCardIndex=14,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only"
"NetworkCardIndex=15,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only"
"NetworkCardIndex=16,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa"
"NetworkCardIndex=17,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only"
"NetworkCardIndex=18,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only"
"NetworkCardIndex=19,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only"
"NetworkCardIndex=20,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa"
"NetworkCardIndex=21,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only"
"NetworkCardIndex=22,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only"
"NetworkCardIndex=23,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only"
"NetworkCardIndex=24,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa"
"NetworkCardIndex=25,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only"
"NetworkCardIndex=26,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only"
"NetworkCardIndex=27,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only"
"NetworkCardIndex=28,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa"
"NetworkCardIndex=29,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only"
"NetworkCardIndex=30,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only"
"NetworkCardIndex=31,DeviceIndex=1,Groups=security_group_id,SubnetId=subnet_id,InterfaceType=efa-only"
...
When launching P5en instances, you can use AWS Deep Learning AMIs (DLAMI) to support EC2 P5en instances. DLAMI provides ML practitioners and researchers with the infrastructure and tools to quickly build scalable, secure, distributed ML applications in preconfigured environments.
You can run containerized ML applications on P5en instances with AWS Deep Learning Containers using libraries for Amazon Elastic Container Service (Amazon ECS) or Amazon Elastic Kubernetes Service (Amazon EKS).
For fast access to large datasets, you can use up to 30 TB of local NVMe SSD storage or virtually unlimited cost-effective storage with Amazon Simple Storage Service (Amazon S3). You can also use Amazon FSx for Lustre file systems in P5en instances so you can access data at the hundreds of GB/s of throughput and millions of input/output operations per second (IOPS) required for large-scale deep learning and HPC workloads.
Now available
Amazon EC2 P5en instances are available today in the US East (Ohio), US West (Oregon), and Asia Pacific (Tokyo) AWS Regions and US East (Atlanta) Local Zone us-east-1-atl-2a through EC2 Capacity Blocks for ML, On Demand, and Savings Plan purchase options. For more information, visit the Amazon EC2 pricing page.
Give Amazon EC2 P5en instances a try in the Amazon EC2 console. To learn more, see Amazon EC2 P5 instance page and send feedback to AWS re:Post for EC2 or through your usual AWS Support contacts.
— Channy