 |
In July, we announced the availability of Llama 3.1 models in Amazon Bedrock. Generative AI technology is improving at incredible speed and today, we are excited to introduce the new Llama 3.2 models from Meta in Amazon Bedrock.
Llama 3.2 offers multimodal vision and lightweight models representing Meta’s latest advancement in large language models (LLMs) and providing enhanced capabilities and broader applicability across various use cases. With a focus on responsible innovation and system-level safety, these new models demonstrate state-of-the-art performance on a wide range of industry benchmarks and introduce features that help you build a new generation of AI experiences.
These models are designed to inspire builders with image reasoning and are more accessible for edge applications, unlocking more possibilities with AI.
The Llama 3.2 collection of models are offered in various sizes, from lightweight text-only 1B and 3B parameter models suitable for edge devices to small and medium-sized 11B and 90B parameter models capable of sophisticated reasoning tasks including multimodal support for high resolution images. Llama 3.2 11B and 90B are the first Llama models to support vision tasks, with a new model architecture that integrates image encoder representations into the language model. The new models are designed to be more efficient for AI workloads, with reduced latency and improved performance, making them suitable for a wide range of applications.
All Llama 3.2 models support a 128K context length, maintaining the expanded token capacity introduced in Llama 3.1. Additionally, the models offer improved multilingual support for eight languages including English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai.
In addition to the existing text capable Llama 3.1 8B, 70B, and 405B models, Llama 3.2 supports multimodal use cases. You can now use four new Llama 3.2 models — 90B, 11B, 3B, and 1B — from Meta in Amazon Bedrock to build, experiment, and scale your creative ideas:
Llama 3.2 90B Vision (text + image input) – Meta’s most advanced model, ideal for enterprise-level applications. This model excels at general knowledge, long-form text generation, multilingual translation, coding, math, and advanced reasoning. It also introduces image reasoning capabilities, allowing for image understanding and visual reasoning tasks. This model is ideal for the following use cases: image captioning, image-text retrieval, visual grounding, visual question answering and visual reasoning, and document visual question answering.
Llama 3.2 11B Vision (text + image input) – Well-suited for content creation, conversational AI, language understanding, and enterprise applications requiring visual reasoning. The model demonstrates strong performance in text summarization, sentiment analysis, code generation, and following instructions, with the added ability to reason about images. This model use cases are similar to the 90B version: image captioning, image-text-retrieval, visual grounding, visual question answering and visual reasoning, and document visual question answering.
Llama 3.2 3B (text input) – Designed for applications requiring low-latency inferencing and limited computational resources. It excels at text summarization, classification, and language translation tasks. This model is ideal for the following use cases: mobile AI-powered writing assistants and customer service applications.
Llama 3.2 1B (text input) – The most lightweight model in the Llama 3.2 collection of models, perfect for retrieval and summarization for edge devices and mobile applications. This model is ideal for the following use cases: personal information management and multilingual knowledge retrieval.
In addition, Llama 3.2 is built on top of the Llama Stack, a standardized interface for building canonical toolchain components and agentic applications, making building and deploying easier than ever. Llama Stack API adapters and distributions are designed to most effectively leverage the Llama model capabilities and it gives customers the ability to benchmark Llama models across different vendors.
Meta has tested Llama 3.2 on over 150 benchmark datasets spanning multiple languages and conducted extensive human evaluations, demonstrating competitive performance with other leading foundation models. Let’s see how these models work in practice.
Using Llama 3.2 models in Amazon Bedrock
To get started with Llama 3.2 models, I navigate to the Amazon Bedrock console and choose Model access on the navigation pane. There, I request access for the new Llama 3.2 models: Llama 3.2 1B, 3B, 11B Vision, and 90B Vision.
To test the new vision capability, I open another browser tab and download from the Our World in Data website the Share of electricity generated by renewables chart in PNG format. The chart is very high resolution and I resize it to be 1024 pixel wide.
Back in the Amazon Bedrock console, I choose Chat under Playgrounds in the navigation pane, select Meta as the category, and choose the Llama 3.2 90B Vision model.
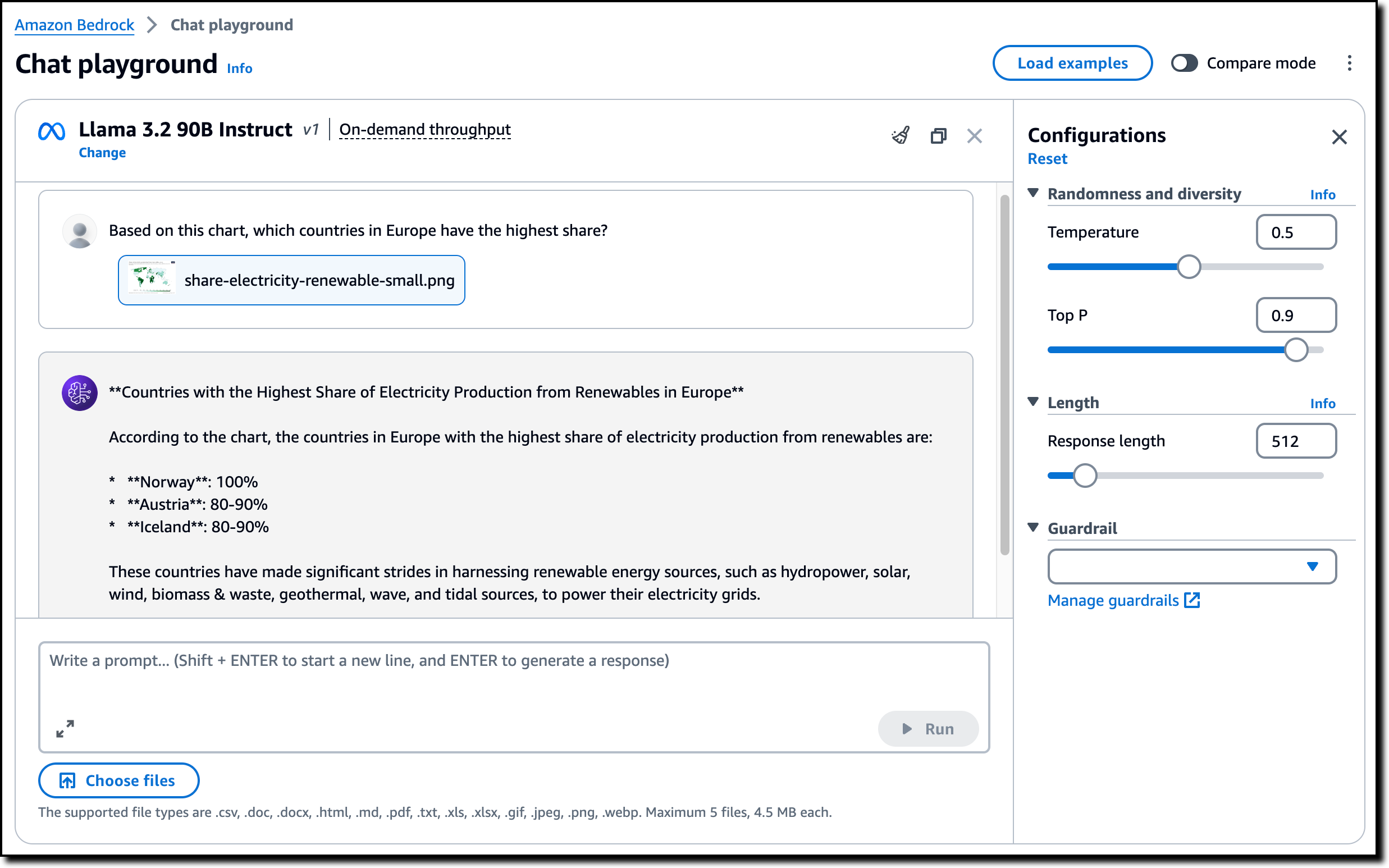
I use Choose files to select the resized chart image and use this prompt:
Based on this chart, which countries in Europe have the highest share?
I choose Run and the model analyzes the image and returns its results:
I can also access the models programmatically using the AWS Command Line Interface (AWS CLI) and AWS SDKs. Compared to using the Llama 3.1 models, I only need to update the model IDs as described in the documentation. I can also use the new cross-region inference endpoint for the US and the EU Regions. These endpoints work for any Region within the US and the EU respectively. For example, the cross-region inference endpoints for the Llama 3.2 90B Vision model are:
us.meta.llama3-2-90b-instruct-v1:0eu.meta.llama3-2-90b-instruct-v1:0
Here’s a sample AWS CLI command using the Amazon Bedrock Converse API. I use the --query parameter of the CLI to filter the result and only show the text content of the output message:
In output, I get the response message from the "assistant".
It’s not much different if you use one of the AWS SDKs. For example, here’s how you can use Python with the AWS SDK for Python (Boto3) to analyze the same image as in the console example:
import boto3
MODEL_ID = "us.meta.llama3-2-90b-instruct-v1:0"
# MODEL_ID = "eu.meta.llama3-2-90b-instruct-v1:0"
IMAGE_NAME = "share-electricity-renewable-small.png"
bedrock_runtime = boto3.client("bedrock-runtime")
with open(IMAGE_NAME, "rb") as f:
image = f.read()
user_message = "Based on this chart, which countries in Europe have the highest share?"
messages = [
{
"role": "user",
"content": [
{"image": {"format": "png", "source": {"bytes": image}}},
{"text": user_message},
],
}
]
response = bedrock_runtime.converse(
modelId=MODEL_ID,
messages=messages,
)
response_text = response["output"]["message"]["content"][0]["text"]
print(response_text)Llama 3.2 models are also available in Amazon SageMaker JumpStart, a machine learning (ML) hub that makes it easy to deploy pre-trained models using the console or programmatically through the SageMaker Python SDK. From SageMaker JumpStart, you can also access and deploy new safeguard models that can help classify the safety level of model inputs (prompts) and outputs (responses), including Llama Guard 3 11B Vision, which are designed to support responsible innovation and system-level safety.
In addition, you can easily fine-tune Llama 3.2 1B and 3B models with SageMaker JumpStart today. Fine-tuned models can then be imported as custom models into Amazon Bedrock. Fine-tuning for the full collection of Llama 3.2 models in Amazon Bedrock and Amazon SageMaker JumpStart is coming soon.
The publicly available weights of Llama 3.2 models make it easier to deliver tailored solutions for custom needs. For example, you can fine-tune a Llama 3.2 model for a specific use case and bring it into Amazon Bedrock as a custom model, potentially outperforming other models in domain-specific tasks. Whether you’re fine-tuning for enhanced performance in areas like content creation, language understanding, or visual reasoning, Llama 3.2’s availability in Amazon Bedrock and SageMaker empowers you to create unique, high-performing AI capabilities that can set your solutions apart.
More on Llama 3.2 model architecture
Llama 3.2 builds upon the success of its predecessors with an advanced architecture designed for optimal performance and versatility:
Auto-regressive language model – At its core, Llama 3.2 uses an optimized transformer architecture, allowing it to generate text by predicting the next token based on the previous context.
Fine-tuning techniques – The instruction-tuned versions of Llama 3.2 employ two key techniques:
- Supervised fine-tuning (SFT) – This process adapts the model to follow specific instructions and generate more relevant responses.
- Reinforcement learning with human feedback (RLHF) – This advanced technique aligns the model’s outputs with human preferences, enhancing helpfulness and safety.
Multimodal capabilities – For the 11B and 90B Vision models, Llama 3.2 introduces a novel approach to image understanding:
- Separately trained image reasoning adaptor weights are integrated with the core LLM weights.
- These adaptors are connected to the main model through cross-attention mechanisms. Cross-attention allows one section of the model to focus on relevant parts of another component’s output, enabling information flow between different sections of the model.
- When an image is input, the model treats the image reasoning process as a “tool use” operation, allowing for sophisticated visual analysis alongside text processing. In this context, tool use is the generic term used when a model uses external resources or functions to augment its capabilities and complete tasks more effectively.
Optimized inference – All models support grouped-query attention (GQA), which enhances inference speed and efficiency, particularly beneficial for the larger 90B model.
This architecture enables Llama 3.2 to handle a wide range of tasks, from text generation and understanding to complex reasoning and image analysis, all while maintaining high performance and adaptability across different model sizes.
Things to know
Llama 3.2 models from Meta are now generally available in Amazon Bedrock in the following AWS Regions:
- Llama 3.2 1B and 3B models are available in the US West (Oregon) and Europe (Frankfurt) Regions, and are available in the US East (Ohio, N. Virginia) and Europe (Ireland, Paris) Regions via cross-region inference.
- Llama 3.2 11B Vision and 90B Vision models are available in the US West (Oregon) Region, and are available in the US East (Ohio, N. Virginia) Regions via cross-region inference.
Check the full AWS Region list for future updates. To estimate your costs, visit the Amazon Bedrock pricing page.
To lean more about how you can use Llama 3.2 11B and 90B models to support vision tasks, read the Vision use cases with Llama 3.2 11B and 90B models from Meta post on the AWS Machine Learning blog channel.
AWS and Meta are also collaborating to bring smaller Llama models to on-device applications, featuring the new 1B and 3B models. For more information, see the Opportunities for telecoms with small language models: Insights from AWS and Meta post on the AWS for Industries blog channel.
To learn more about Llama 3.2 features and capabilities, visit the Llama models section of the Amazon Bedrock documentation. Give Llama 3.2 a try in the Amazon Bedrock console today, and send feedback to AWS re:Post for Amazon Bedrock.
You can find deep-dive technical content and discover how our Builder communities are using Amazon Bedrock at community.aws. Let us know what you build with Llama 3.2 in Amazon Bedrock!
— Danilo

