|
Today, I’m happy to share that Automated Reasoning checks, a new Amazon Bedrock Guardrails policy that we previewed during AWS re:Invent, is now generally available. Automated Reasoning checks helps you validate the accuracy of content generated by foundation models (FMs) against a domain knowledge. This can help prevent factual errors due to AI hallucinations. The policy uses mathematical logic and formal verification techniques to validate accuracy, providing definitive rules and parameters against which AI responses are checked for accuracy.
This approach is fundamentally different from probabilistic reasoning methods which deal with uncertainty by assigning probabilities to outcomes. In fact, Automated Reasoning checks delivers up to 99% verification accuracy, providing provable assurance in detecting AI hallucinations while also assisting with ambiguity detection when the output of a model is open to more than one interpretation.
With general availability, you get the following new features:
- Support for large documents in a single build, up to 80K tokens – Process extensive documentation; we found this can add up to 100 pages of content
- Simplified policy validation – Save your validation tests and run them repeatedly, making it easier to maintain and verify your policies over time
- Automated scenario generation – Create test scenarios automatically from your definitions, saving time and effort while helping make coverage more comprehensive
- Enhanced policy feedback – Provide natural language suggestions for policy changes, simplifying the way you can improve your policies
- Customizable validation settings – Adjust confidence score thresholds to match your specific needs, giving you more control over validation strictness
Let’s see how this works in practice.
Creating Automated Reasoning checks in Amazon Bedrock Guardrails
To use Automated Reasoning checks, you first encode rules from your knowledge domain into an Automated Reasoning policy, then use the policy to validate generated content. For this scenario, I’m going to create a mortgage approval policy to safeguard an AI assistant evaluating who can qualify for a mortgage. It is important that the predictions of the AI system do not deviate from the rules and guidelines established for mortgage approval. These rules and guidelines are captured in a policy document written in natural language.
In the Amazon Bedrock console, I choose Automated Reasoning from the navigation pane to create a policy.
I enter name and description of the policy and upload the PDF of the policy document. The name and description are just metadata and do not contribute in building the Automated Reasoning policy. I describe the source content to add context on how it should be translated into formal logic. For example, I explain how I plan to use the policy in my application, including sample Q&A from the AI assistant.
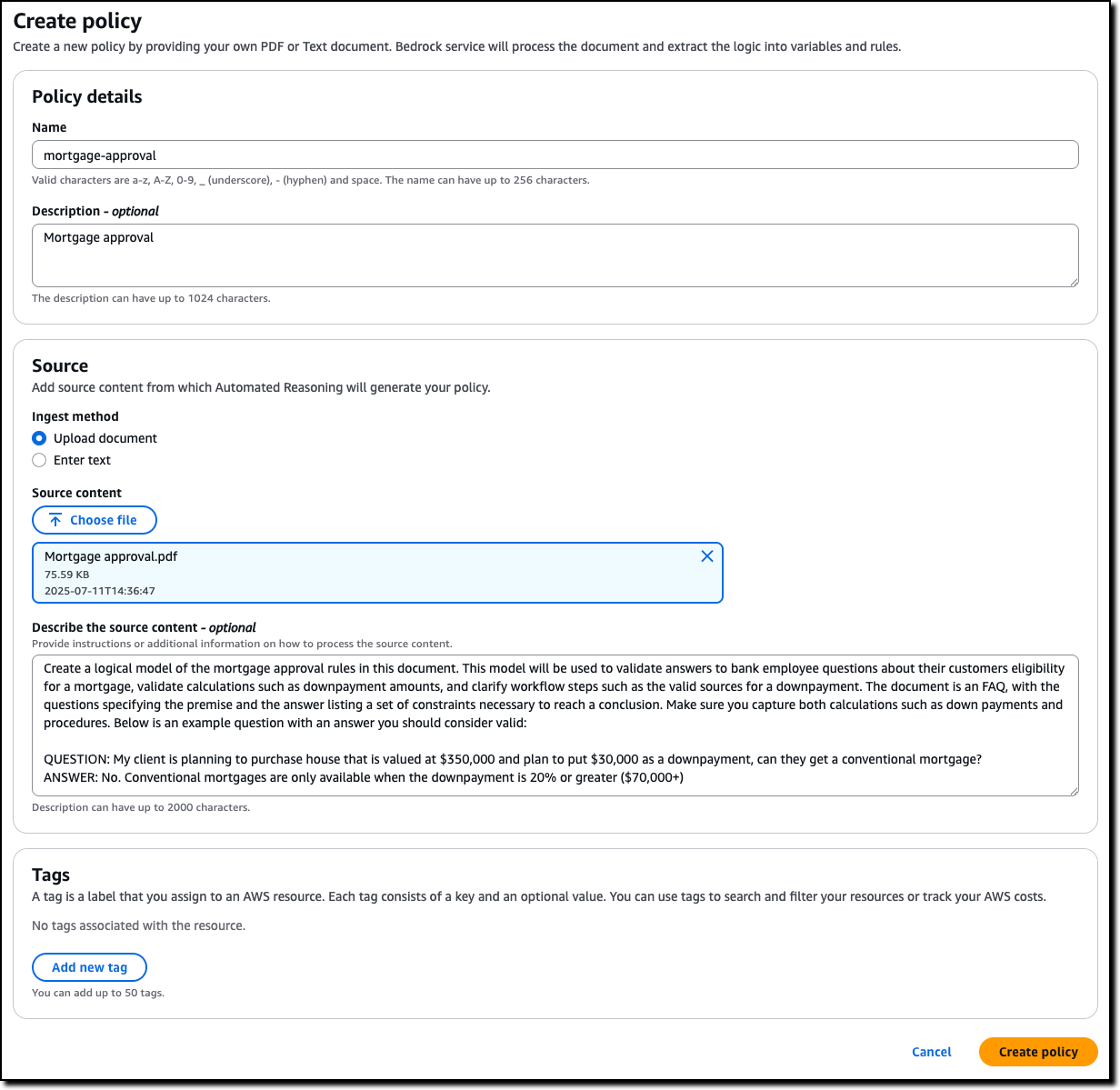
When the policy is ready, I land on the overview page, showing the policy details and a summary of the tests and definitions. I choose Definitions from the dropdown to examine the Automated Reasoning policy, made of rules, variables, and types that have been created to translate the natural language policy into formal logic.
The Rules describe how variables in the policy are related and are used when evaluating the generated content. For example, in this case, which are the thresholds to apply and how some of the decisions are taken. For traceability, each rule has its own unique ID.
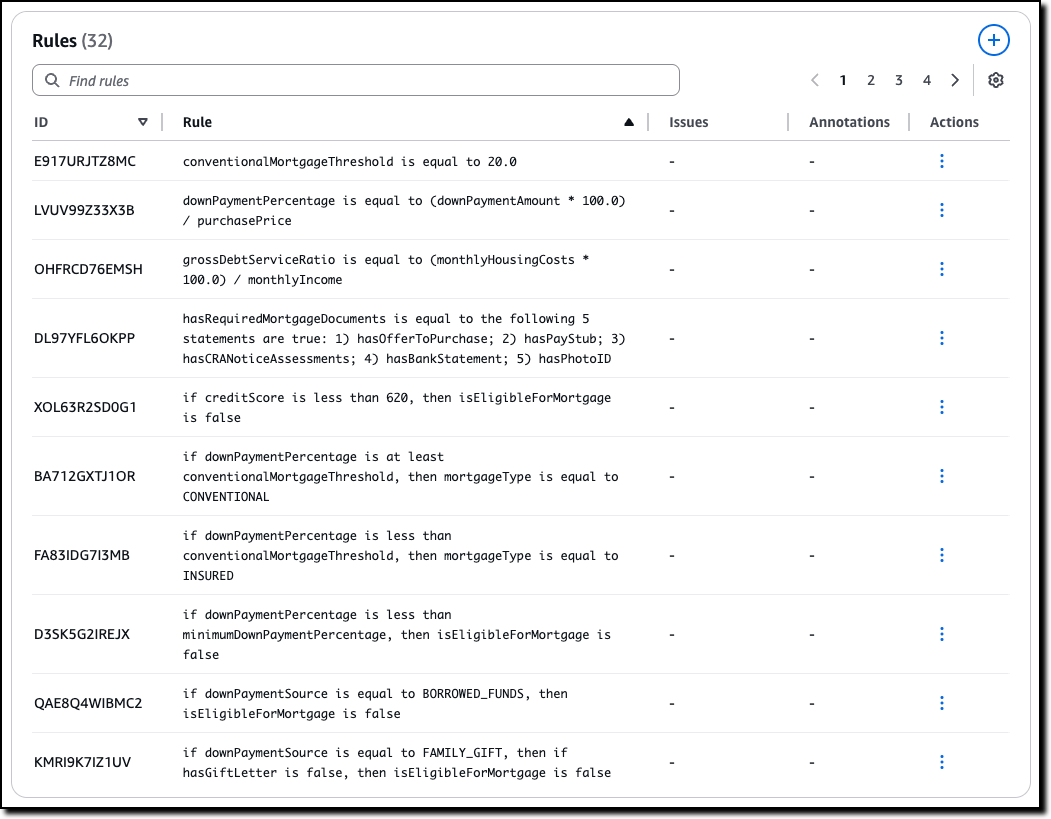
The Variables represent the main concepts at play in the original natural language documents. Each variable is involved in one or more rules. Variables allow complex structures to be easier to understand. For this scenario, some of the rules need to look at the down payment or at the credit score.
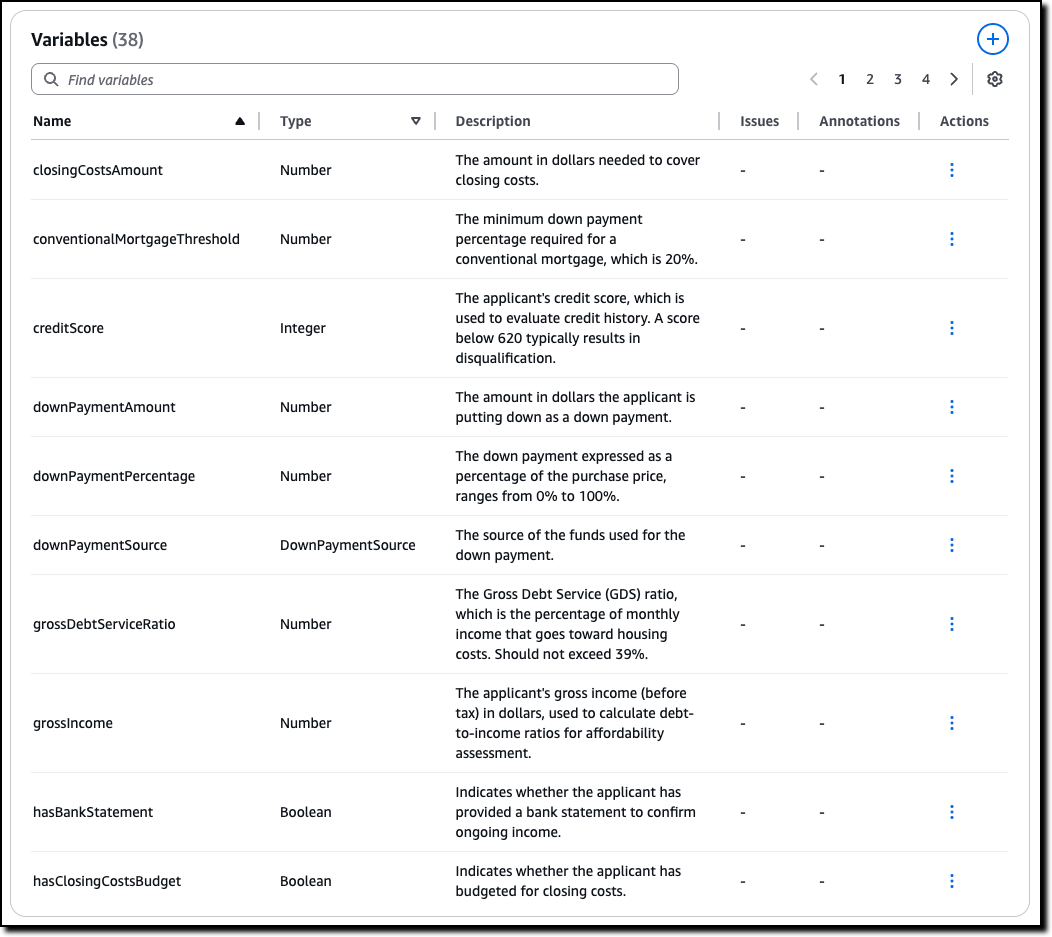
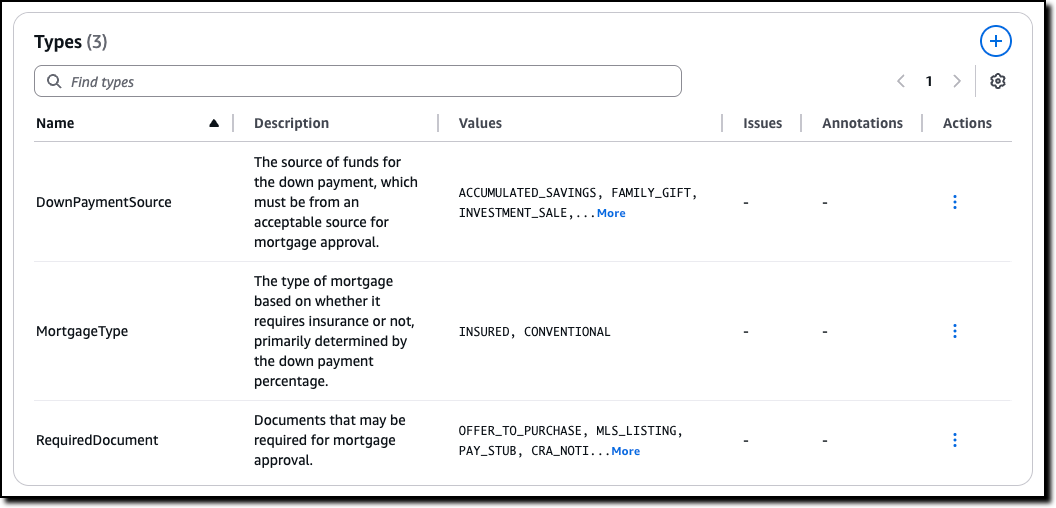
Custom Types are created for variables that are neither boolean nor numeric. For example, for variables that can only assume a limited number of values. In this case, there are two type of mortgage described in the policy, insured and conventional.
Now we can assess the quality of the initial Automated Reasoning policy through testing. I choose Tests from the dropdown. Here I can manually enter a test, consisting of input (optional) and output, such as a question and its possible answer from the interaction of a customer with the AI assistant. I then set the expected result from the Automated Reasoning check. The expected result can be valid (the answer is correct), invalid (the answer is not correct), or satisfiable (the answer could be true or false depending on specific assumptions). I can also assign a confidence threshold for the translation of the query/content pair from natural language to logic.
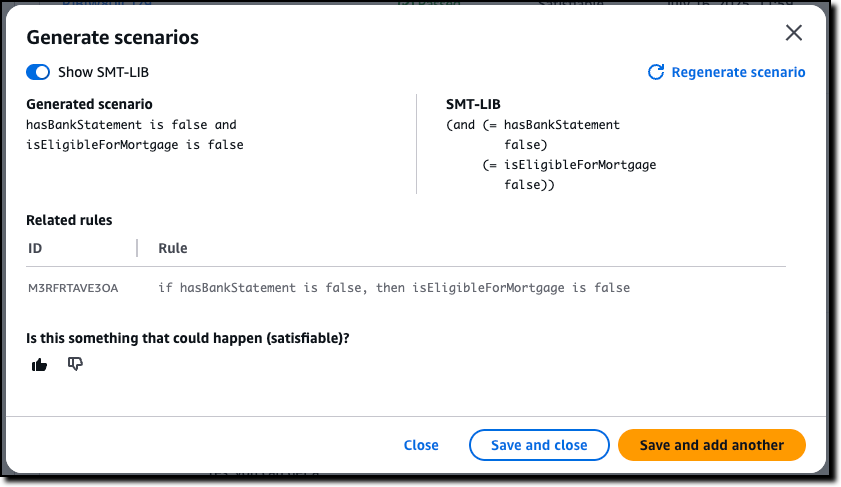
Before I enter tests manually, I use the option to automatically generate a scenario from the definitions. This is the easiest way to validate a policy and (unless you’re an expert in logic) should be the first step after the creation of the policy.
For each generated scenario, I provide an expected validation to say if it is something that can happen (satisfiable) or not (invalid). If not, I can add an annotation that can then be used to update the definitions. For a more advanced understanding of the generated scenario, I can show the formal logic representation of a test using SMT-LIB syntax.
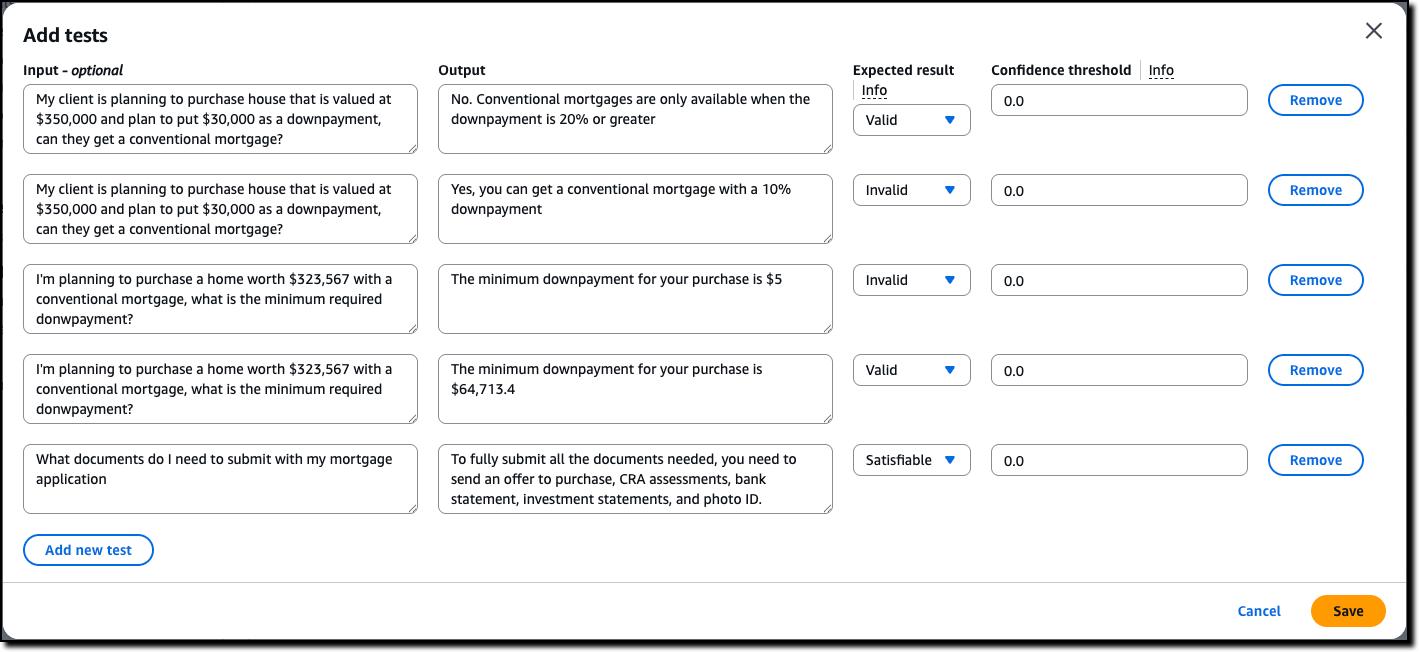
After using the generate scenario option, I enter a few tests manually. For these tests, I set different expected results: some are valid, because they follow the policy, some are invalid, because they flout the policy, and some are satisfiable, because their result depends on specific assumptions.
Then, I choose Validate all tests to see the results. All tests passed in this case. Now, when I update the policy, I can use these tests to validate that the changes didn’t introduce errors.
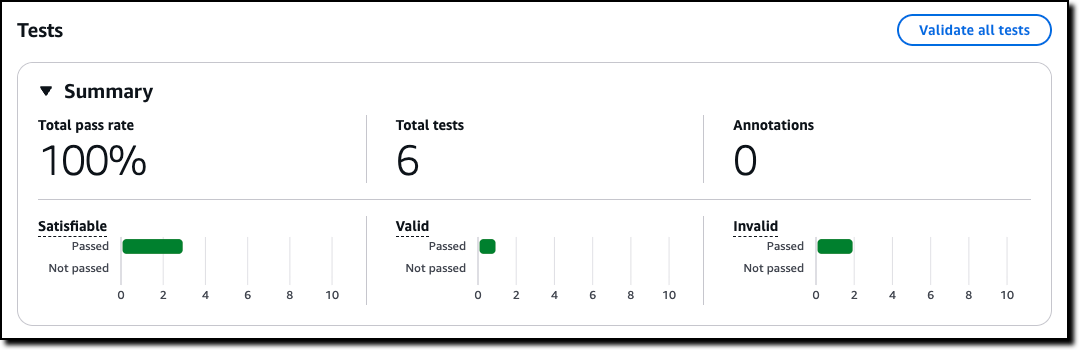
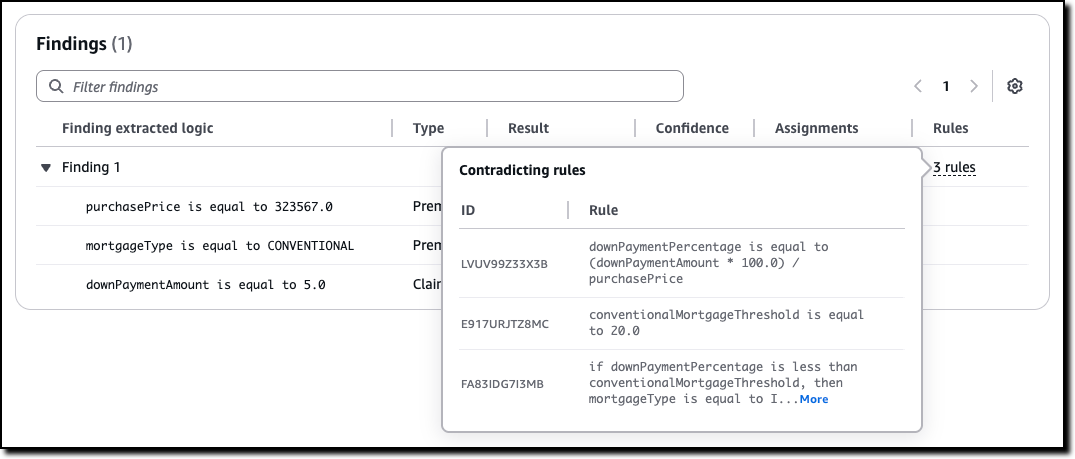
For each test, I can look at the findings. If a test doesn’t pass, I can look at the rules that created the contradiction that made the test fail and go against the expected result. Using this information, I can understand if I should add an annotation, to improve the policy, or correct the test.
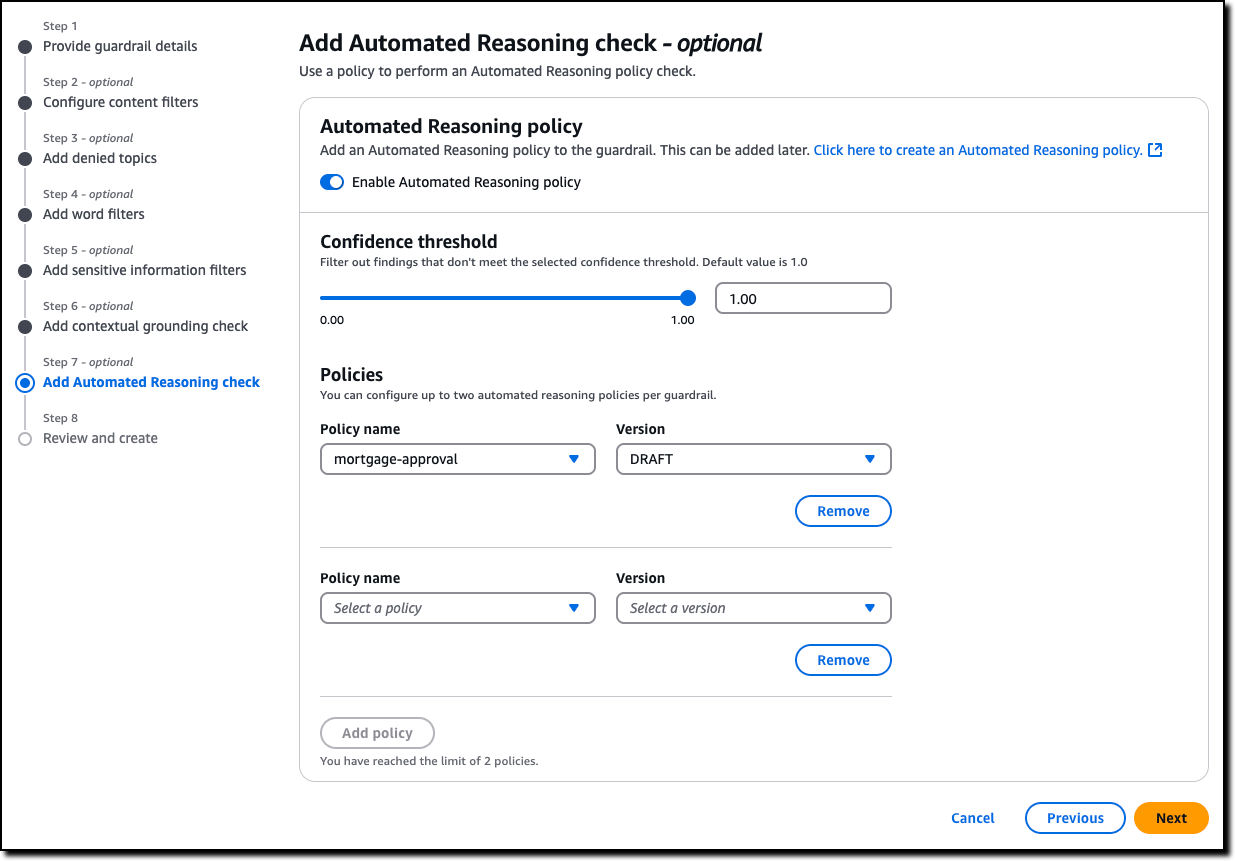
Now that I’m satisfied with the tests, I can create a new Amazon Bedrock guardrail (or update an existing one) to use up to two Automated Reasoning policies to check the validity of the responses of the AI assistant. All six policies offered by Guardrails are modular, and can be used together or separately. For example, Automated Reasoning checks can be used with other safeguards such as content filtering and contextual grounding checks. The guardrail can be applied to models served by Amazon Bedrock or with any third-party model (such as OpenAI and Google Gemini) via the ApplyGuardrail API. I can also use the guardrail with an agent framework such as Strands Agents, including agents deployed using Amazon Bedrock AgentCore.
Now that we saw how to set up a policy, let’s look at how Automated Reasoning checks are used in practice.
Customer case study – Utility outage management systems
When the lights go out, every minute counts. That’s why utility companies are turning to AI solutions to improve their outage management systems. We collaborated on a solution in this space together with PwC. Using Automated Reasoning checks, utilities can streamline operations through:
- Automated protocol generation – Creates standardized procedures that meet regulatory requirements
- Real-time plan validation – Ensures response plans comply with established policies
- Structured workflow creation – Develops severity-based workflows with defined response targets
At its core, this solution combines intelligent policy management with optimized response protocols. Automated Reasoning checks are used to assess AI-generated responses. When a response is found to be invalid or satisfiable, the result of the Automated Reasoning check is used to rewrite or enhance the answer.
This approach demonstrates how AI can transform traditional utility operations, making them more efficient, reliable, and responsive to customer needs. By combining mathematical precision with practical requirements, this solution sets a new standard for outage management in the utility sector. The result is faster response times, improved accuracy, and better outcomes for both utilities and their customers.
In the words of Matt Wood, PwC’s Global and US Commercial Technology and Innovation Officer:
“At PwC, we’re helping clients move from AI pilot to production with confidence—especially in highly regulated industries where the cost of a misstep is measured in more than dollars. Our collaboration with AWS on Automated Reasoning checks is a breakthrough in responsible AI: mathematically assessed safeguards, now embedded directly into Amazon Bedrock Guardrails. We’re proud to be AWS’s launch collaborator, bringing this innovation to life across sectors like pharma, utilities, and cloud compliance—where trust isn’t a feature, it’s a requirement.”
Things to know
Automated Reasoning checks in Amazon Bedrock Guardrails is generally available today in the following AWS Regions: US East (Ohio, N. Virginia), US West (Oregon), and Europe (Frankfurt, Ireland, Paris).
With Automated Reasoning checks, you pay based on the amount of text processed. For more information, see Amazon Bedrock pricing.
To learn more, and build secure and safe AI applications, see the technical documentation and the GitHub code samples. Follow this link for direct access to the Amazon Bedrock console.
The videos in this playlist include an introduction to Automated Reasoning checks, a deep dive presentation, and hands-on tutorials to create, test, and refine a policy. This is the second video in the playlist, where my colleague Wale provides a nice intro to the capability.
— Danilo