Why does JavaScript have so many eccentricities!? Like, why does 0.2 + 0.1 equals 0.30000000000000004? Or, why does "" == false evaluate to true?
There are a lot of mind-boggling decisions in JavaScript that seem pointless; some are misunderstood, while others are direct missteps in the design. Regardless, it’s worth knowing what these strange things are and why they are in the language. I’ll share what I believe are some of the quirkiest things about JavaScript and make sense of them.
0.1 + 0.2 And The Floating Point Format
Contents
Many of us have mocked JavaScript by writing 0.1 + 0.2 in the console and watching it resoundingly fail to get 0.3, but rather a funny-looking 0.30000000000000004 value.
What many developers might not know is that the weird result is not really JavaScript’s fault! JavaScript is merely adhering to the IEEE Standard for Floating-Point Arithmetic that nearly every other computer and programming language uses to represent numbers.
But what exactly is the Floating-Point Arithmetic?
Computers have to represent numbers in all sizes, from the distance between planets and even between atoms. On paper, it’s easy to write a massive number or a minuscule quantity without worrying about the size it will take. Computers don’t have that luxury since they have to save all kinds of numbers in binary and a small space in memory.
Take an 8-bit integer, for example. In binary, it can hold integers ranging from 0 to 255.
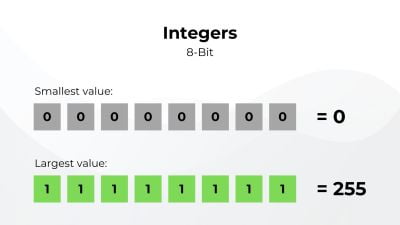
The keyword here is integers. It can’t represent any decimals between them. To fix this, we could add an imaginary decimal point somewhere along our 8-bit so the bits before the point are used to represent the integer part and the rest are used for the decimal part. Since the point is always in the same imaginary spot, it’s called a fixed point decimal. But it comes with a great cost since the range is reduced from 0 to 255 to exactly 0 to 15.9375.
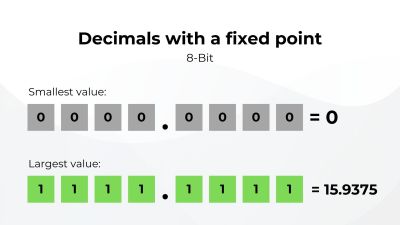
Having greater precision means sacrificing range, and vice versa. We also have to take into consideration that computers need to please a large number of users with different requirements. An engineer building a bridge doesn’t worry too much if the measurements are off by just a little, say a hundredth of a centimeter. But, on the other hand, that same hundredth of a centimeter can end up costing much more for someone making a microchip. The precision that’s needed is different, and the consequences of a mistake can vary.
Another consideration is the size where numbers are stored in memory since storing long numbers in something like a megabyte isn’t feasible.
The floating-point format was born from this need to represent both large and small quantities with precision and efficiency. It does so in three parts:
- A single bit that represents whether or not the number is positive or negative (
0for positive,1for negative). - A significand or mantissa that contains the number’s digits.
- An exponent specifies where the decimal (or binary) point is placed relative to the beginning of the mantissa, similar to how scientific notation works. Consequently, the point can move around to any position, hence the floating point.
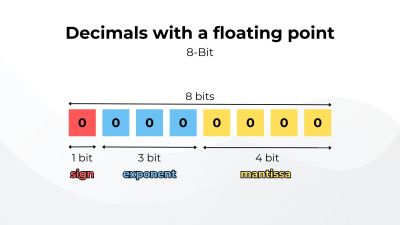
An 8-bit floating-point format can represent numbers between 0.0078 to 480 (and its negatives), but notice that the floating-point representation can’t represent all of the numbers in that range. It’s impossible since 8 bits can represent only 256 distinct values. Inevitably, many numbers cannot be accurately represented. There are gaps along the range. Computers, of course, work with more bits to increase accuracy and range, commonly with 32-bits and 64-bits, but it’s impossible to represent all numbers accurately, a small price to pay if we consider the range we gain and the memory we save.
The exact dynamics are far more complex, but for now, we only have to understand that while this format allows us to express numbers in a large range, it loses precision (the gaps between representable values get bigger) when they become too big. For example, JavaScript numbers are presented in a double-precision floating-point format, i.e., each number is represented in 64 bits in memory, leaving 53 bits to represent the mantissa. That means JavaScript can only safely represent integers between –(253 — 1) and 253 — 1 without losing precision. Beyond that, the arithmetic stops making sense. That’s why we have the Number.MAX_SAFE_INTEGER static data property to represent the maximum safe integer in JavaScript, which is (253 — 1) or 9007199254740991.
But 0.3 is obviously below the MAX_SAFE_INTEGER threshold, so why can’t we get it when adding 0.1 and 0.2? The floating-point format struggles with some fractional numbers. It isn’t a problem with the floating-point format, but it certainly is across any number system.
To see this, let’s represent one-third (1⁄3) in base-10.
0.3
0.33
0.3333333 [...]
No matter how many digits we try to write, the result will never be exactly one-third. In the same way, we cannot accurately represent some fractional numbers in base-2 or binary. Take, for example, 0.2. We can write it with no problem in base-10, but if we try to write it in binary we get a recurring 1001 at the end that repeats infinitely.
0.001 1001 1001 1001 1001 1001 10 [...]
We obviously can’t have an infinitely large number, so at some point, the mantissa has to be truncated, making it impossible not to lose precision in the process. If we try to convert 0.2 from double-precision floating-point back to base-10, we will see the actual value saved in memory:
0.200000000000000011102230246251565404236316680908203125
It isn’t 0.2! We cannot represent an awful lot of fractional values — not only in JavaScript but in almost all computers. So why does running 0.2 + 0.2 correctly compute 0.4? In this case, the imprecision is so small that it gets rounded by Javascript (at the 16th decimal), but sometimes the imprecision is enough to escape the rounding mechanism, as is the case with 0.2 + 0.1. We can see what’s happening under the hood if we try to sum the actual values of 0.1 and 0.2.
This is the actual value saved when writing 0.1:
0.1000000000000000055511151231257827021181583404541015625
If we manually sum up the actual values of 0.1 and 0.2, we will see the culprit:
0.3000000000000000444089209850062616169452667236328125
That value is rounded to 0.30000000000000004. You can check the real values saved at float.exposed.
Floating-point has its known flaws, but its positives outweigh them, and it’s standard around the world. In that sense, it’s actually a relief when all modern systems will give us the same 0.30000000000000004 result across architectures. It might not be the result you expect, but it’s a result you can predict.

Type Coercion
JavaScript is a dynamically typed language, meaning we don’t have to declare a variable’s type, and it can be changed later in the code.
I find dynamically typed languages liberating since we can focus more on the substance of the code.
The issue comes from being weakly typed since there are many occasions where the language will try to do an implicit conversion between different types, e.g., from strings to numbers or falsy and truthy values. This is specifically true when using the equality ( ==) and plus sign (+) operators. The rules for type coercion are intricate, hard to remember, and even incorrect in certain situations. It’s better to avoid using == and always prefer the strict equality operator (===).
For example, JavaScript will coerce a string to a number when compared with another number:
console.log("2" == 2); // true
The inverse applies to the plus sign operator (+). It will try to coerce a number into a string when possible:
console.log(2 + "2"); // "22"
That’s why we should only use the plus sign operator (+) if we are sure that the values are numbers. When concatenating strings, it’s better to use the concat() method or template literals.
The reason such coercions are in the language is actually absurd. When JavaScript creator Brendan Eich was asked what he would have done differently in JavaScript’s design, his answer was to be more meticulous in the implementations early users of the language wanted:
“I would have avoided some of the compromises that I made when I first got early adopters, and they said, “Can you change this?”
— Brendan Eich
The most glaring example is the reason why we have two equality operators, == and ===. When an early JavaScript user prompted his need to compare a number to a string without having to change his code to make a conversion, Brendan added the loose equality operator to satisfy those needs.
There are a lot of other rules governing the loose equality operator (and other statements checking for a condition) that make JavaScript developers scratch their heads. They are complex, tedious, and senseless, so we should avoid the loose equality operator (==) at all costs and replace it with its strict homonym (===).
Why do we have two equality operators in the first place? A lot of factors, but we can point a finger at Guy L. Steele, co-creator of the Scheme programming language. He assured Eich that we could always add another equality operator since there were dialects with five distinct equality operators in the Lisp language! This mentality is dangerous, and nowadays, all features have to be rigorously analyzed because we can always add new features, but once they are in the language, they cannot be removed.
Automatic Semicolon Insertion
When writing code in JavaScript, a semicolon (;) is required at the end of some statements, including:
var,let,const;- Expression statements;
do...while;continue,break,return,throw;debugger;- Class field declarations (public or private);
import,export.
That said, we don’t necessarily have to insert a semicolon every time since JavaScript can automatically insert semicolons in a process unsurprisingly known as Automatic Semicolon Insertion (ASI). It was intended to make coding easier for beginners who didn’t know where a semicolon was needed, but it isn’t a reliable feature, and we should stick to explicitly typing where a semicolon goes. Linters and formatters add a semicolon where ASI would, but they aren’t completely reliable either.
ASI can make some code work, but most of the time it doesn’t. Take the following code:
const a = 1
(1).toString()
const b = 1
[1, 2, 3].forEach(console.log)
You can probably see where the semicolons go, and if we formatted it correctly, it would end up as:
const a = 1;
(1).toString();
const b = 1;
[(1, 2, 3)].forEach(console.log);
But if we feed the prior code directly to JavaScript, all kinds of exceptions would be thrown since it would be the same as writing this:
const a = 1(1).toString();
const b = (1)[(1, 2, 3)].forEach(console.log);
In conclusion, know your semicolons.
Why So Many Bottom Values?
The term “bottom” is often used to represent a value that does not exist or is undefined. But why do we have two kinds of bottom values in JavaScript?
Everything in JavaScript can be considered an object, except the two bottom values null and undefined (despite typeof null returning object). Attempting to get a property value from them raises an exception.
Note that, strictly speaking, all primitive values aren’t objects. But only null and undefined aren’t subjected to boxing.
We can even think of NaN as a third bottom value that represents the absence of a number. The abundance of bottom values should be regarded as a design error. There isn’t a straightforward reason that explains the existence of two bottom values, but we can see a difference in how JavaScript employs them.
undefined is the bottom value that JavaScript uses by default, so it’s considered good practice to use it exclusively in your code. When we define a variable without an initial value, attempting to retrieve it assigns the undefined value. The same thing happens when we try to access a non-existing property from an object. To match JavaScript’s behavior as closely as possible, use undefined to denote an existing property or variable that doesn’t have a value.
On the other hand, null is used to represent the absence of an object (hence, its typeof returns an object even though it isn’t). However, this is considered a design blunder because undefined could fulfill its purposes as effectively. It’s used by JavaScript to denote the end of a recursive data structure. More specifically, it’s used in the prototype chain to denote its end. Most of the time, you can use undefined over null, but there are some occasions where only null can be used, as is the case with Object.create in which we can only create an object without a prototype passing null; using undefined returns a TypeError.
null and undefined both suffer from the path problem. When trying to access a property from a bottom value — as if they were objects — exceptions are raised.
let user;
let userName = user.name; // Uncaught TypeError
let userNick = user.name.nick; // Uncaught TypeError
There is no way around this unless we check for each property value before trying to access the next one, either using the logical AND (&&) or optional chaining (?).
let user;
let userName = user?.name;
let userNick = user && user.name && user.name.nick;
console.log(userName); // undefined
console.log(userNick); // undefined
I said that NaN can be considered a bottom value, but it has its own confusing place in JavaScript since it represents numbers that aren’t actual numbers, usually due to a failed string-to-number conversion (which is another reason to avoid it). NaN has its own shenanigans because it isn’t equal to itself! To test if a value is NaN or not, use Number.isNaN().
We can check for all three bottom values with the following test:
function stringifyBottom(bottomValue) {
if (bottomValue === undefined) {
return "undefined";
}
if (bottomValue === null) {
return "null";
}
if (Number.isNaN(bottomValue)) {
return "NaN";
}
}
Increment (++) And Decrement (--)
As developers, we tend to spend more time reading code rather than writing it. Whether we are reading documentation, reviewing someone else’s work, or checking our own, code readability will increase our productivity over brevity. In other words, readability saves time in the long run.
That’s why I prefer using + 1 or - 1 rather than the increment (++) and decrement (--) operators.
It’s illogical to have a different syntax exclusively for incrementing a value by one in addition to having a pre-increment form and a post-increment form, depending on where the operator is placed. It is very easy to get them reversed, and that can be difficult to debug. They shouldn’t have a place in your code or even in the language as a whole when we consider where the increment operators come from.
As we saw in a previous article, JavaScript syntax is heavily inspired by the C language, which uses pointer variables. Pointer variables were designed to store the memory addresses of other variables, enabling dynamic memory allocation and manipulation. The ++ and -- operators were originally crafted for the specific purpose of advancing or stepping back through memory locations.
Nowadays, pointer arithmetic has been proven harmful and can cause accidental access to memory locations beyond the intended boundaries of arrays or buffers, leading to memory errors, a notorious source of bugs and vulnerabilities. Regardless, the syntax made its way to JavaScript and remains there today.
While the use of ++ and -- remains a standard among developers, an argument for readability can be made. Opting for + 1 or - 1 over ++ and -- not only aligns with the principles of clarity and explicitness but also avoids having to deal with its pre-increment form and post-increment form.
Overall, it isn’t a life-or-death situation but a nice way to make your code more readable.
Conclusion
JavaScript’s seemingly senseless features often arise from historical decisions, compromises, and attempts to cater to all needs. Unfortunately, it’s impossible to make everyone happy, and JavaScript is no exception.
JavaScript doesn’t have the responsibility to accommodate all developers, but each developer has the responsibility to understand the language and embrace its strengths while being mindful of its quirks.
I hope you find it worth your while to keep learning more and more about JavaScript and its history to get a grasp of its misunderstood features and questionable decisions. Take its amazing prototypal nature, for example. It was obscured during development or blunders like the this keyword and its multipurpose behavior.
Either way, I encourage every developer to research and learn more about the language. And if you’re interested, I go a bit deeper into questionable areas of JavaScript’s design in another article published here on Smashing Magazine!
(gg, yk)


